📅December 14th, 2022
Summary: I'm making a case for a certain type of debugger.
More detail below.
A couple times people trying to get into ROM patching ask me what tool I use. I'll answer, although it's not the popular answer. It takes some getting used to because of type of debugging it is and for other reasons.
What I use for most of my patching stuff is Geiger's SNES debugger. It's a special build of Snes9x with a debugger bolted on.
Looks like this
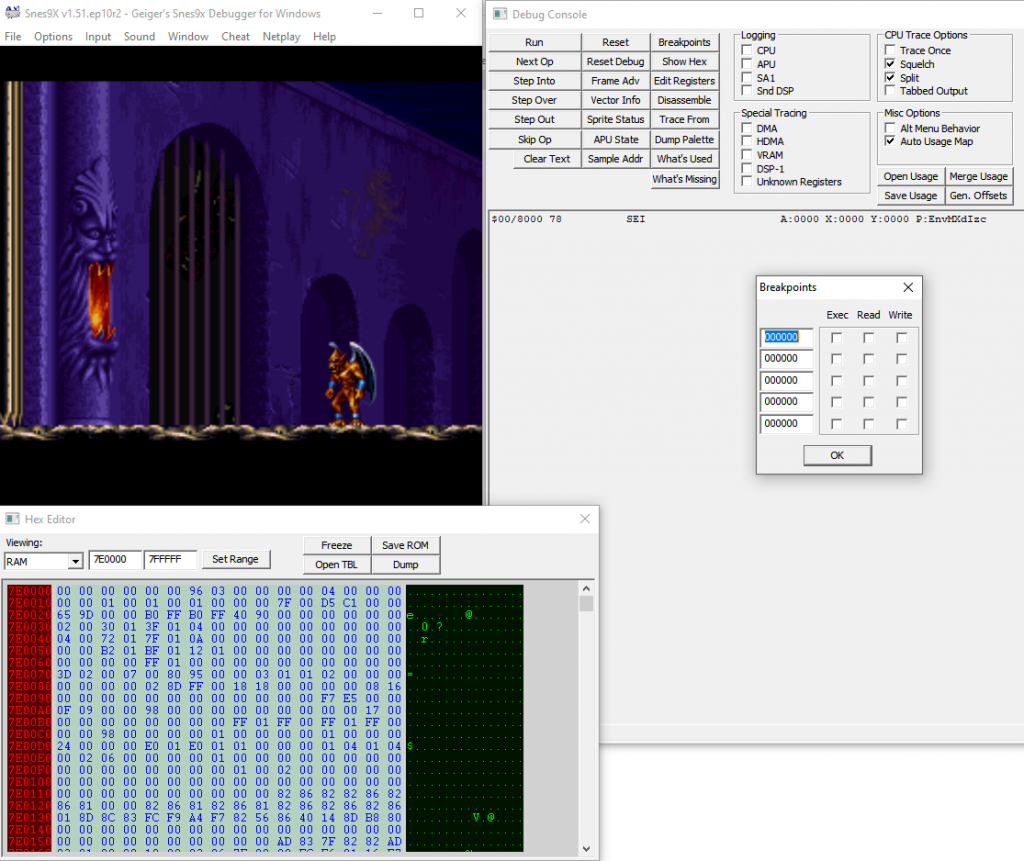
The game, main debugger interface, and memory view are in different windows. You press the 'Breakpoints' button to get a pop-up dialog for setting those. Looks very Win32 ish.
Why not for everyone?
When I first started looking into debugging SNES it was a while ago, this was one of the best options available.
Since then, the world has moved on.
Despite the age of the SNES today, there is a lot of information out there sourced by fans and tools under active development.
Today, there are SNES debuggers that
- have larger feature sets
- have been tested more thoroughly to weed out issues
- have interfaces that suit newer UI/UX paradigms
- are actively developed
- are open-source and so are easy to extend
The debugger has some 'personality traits' I've gotten used to working around. Here's a list of what they are in case you run into them.
Issue: Breakpoints don't hit after certain operations (e.g., save state load)
Workaround: Re-open the breakpoint window, and click OK.
Issue: Step Out doesn't step out to the expected place
Workaround: Don't rely on Step Out for function calls that straddle any interrupts.
Issue: 'Show Hex' (memory) window shows blank ROM on 1st open
Workaround: Choose something (e.g., RAM) 'viewing' dropdown then go back to ROM.
Issue: Emulator crash if you scroll too far down in the memory window
Workaround: Don't use invalid ranges. Don't try to scroll past the end of the range.
Issue: Can not view CGRAM or OAM
Workaround: Use a different debugger.
Issue: Can not view DBR or PBR
Workaround: Edit some code to push them (PHB/PHK) then PLA.
Software
The debugger isn't under active development anymore so things like the above list are what they are. I contacted Geiger asking for the source code. He responded wishing me well, and wouldn't give it to me for various reasons which is his perogative.
None of these were bad enough to block me, it's been alright.
They also weren't severe enough to be motivating to go in and fix them in this closed-source program.
Why I use it
Despite the above things, I still use it for a few reasons.
- Habit. I know my way around it
- The most complicated parts of what I need to do aren't actually through a debugger, (e.g., 'special diffing' of memory dumps), and a debugger could never do as good a job as flexible-function code.
- Transcript-style debugging.
The biggest one is transcript debugging.
For transcript-style debugging see explanation below.
Transcript-style debugging
For ROM patching projects where the patch is a small targeted surface area, generally speaking you're not trying to recover source code.
Recovering source code so that you can work in it is something you can do if you really want. You can do it if it makes you happy. But it's not always crucial. It can even be a distraction. Be it in an assembly language or a higher-level language like C/C++, recovering source code can be unnecessary for your goal of a targeted change in behavior and can make the task way less efficient.
To get better at this kind of reverse-engineering task, and this is hard for a lot of people to hear-- you need to fall out of love with source code written in programming languages. This includes source-level debugging, it includes expressions of flow control, and this includes source code written in assembly languages.
Below is an example of a debugger listing not using source-level debugging, and using transcript-style debugging instead:
$80/BC3A 20 B0 C1 JSR $C1B0 [$80:C1B0] A:0000 X:00A9 Y:0005 P:envmXdizc
$80/C1B0 64 6F STZ $6F [$00:006F] A:0000 X:00A9 Y:0005 P:envmXdizc
$80/C1B2 A5 6C LDA $6C [$00:006C] A:0000 X:00A9 Y:0005 P:envmXdizc
$80/C1B4 0A ASL A A:3640 X:00A9 Y:0005 P:envmXdizc
$80/C1B5 88 DEY A:6C80 X:00A9 Y:0005 P:envmXdizc
$80/C1B6 F0 13 BEQ $13 [$C1CB] A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1B8 90 38 BCC $38 [$C1F2] A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1F2 86 00 STX $00 [$00:0000] A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1F4 A2 02 LDX #$02 A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1F6 0A ASL A A:6C80 X:0002 Y:0004 P:envmXdizc
$80/C1F7 88 DEY A:D900 X:0002 Y:0004 P:eNvmXdizc
$80/C1F8 F0 20 BEQ $20 [$C21A] A:D900 X:0002 Y:0003 P:envmXdizc
$80/C1FA E8 INX A:D900 X:0002 Y:0003 P:envmXdizc
$80/C1FB 90 F9 BCC $F9 [$C1F6] A:D900 X:0003 Y:0003 P:envmXdizc
$80/C1F6 0A ASL A A:D900 X:0003 Y:0003 P:envmXdizc
$80/C1F7 88 DEY A:B200 X:0003 Y:0003 P:eNvmXdizC
$80/C1F8 F0 20 BEQ $20 [$C21A] A:B200 X:0003 Y:0002 P:envmXdizC"But isn't this source code in assembly language?" I heard this question before. I think this confusion comes from people who haven't done much forward engineering with assembly languages yet, forget reverse engineering.
The above is not source code, it's a debugger transcript.
Again, it's not source code, it's printout of what got executed, one instruction at a time.
Dead giveaways that it's not source code
- Every line starts with an address
- Every line ends with register state
- There's a function call and then the stepped-into body immediately after. Not proper for source code
- Some instructions are repeated, like $80/C1F6, $80/C1F7, $80/C1F8. This is a loop
Thinking it's source code is pretty uncharitable to the readability of source code, which usually uses more identifiers and comments and labels and stuff than this example has.
The transcript looks different from source code, and transcript debugging is different from source style debugging.
How is transcript debugging different?
Now that we know what transcripts are: transcript-style debugging is different from source-style, or traditional debugging.
See an example of source-style debugging, with No$sns:
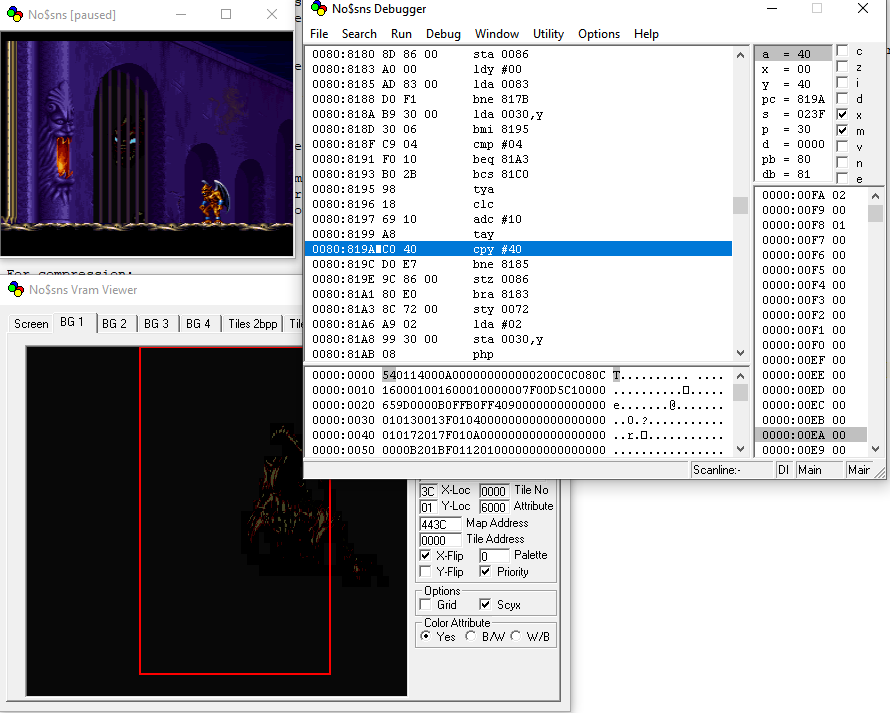
There's a window. In the window, the local disassembly appears in a listing, with the current instruction highlighted in blue. The local disassembly shows instructions laid out in one contiguous block of memory.
Or, here's another debugger, bsnes:
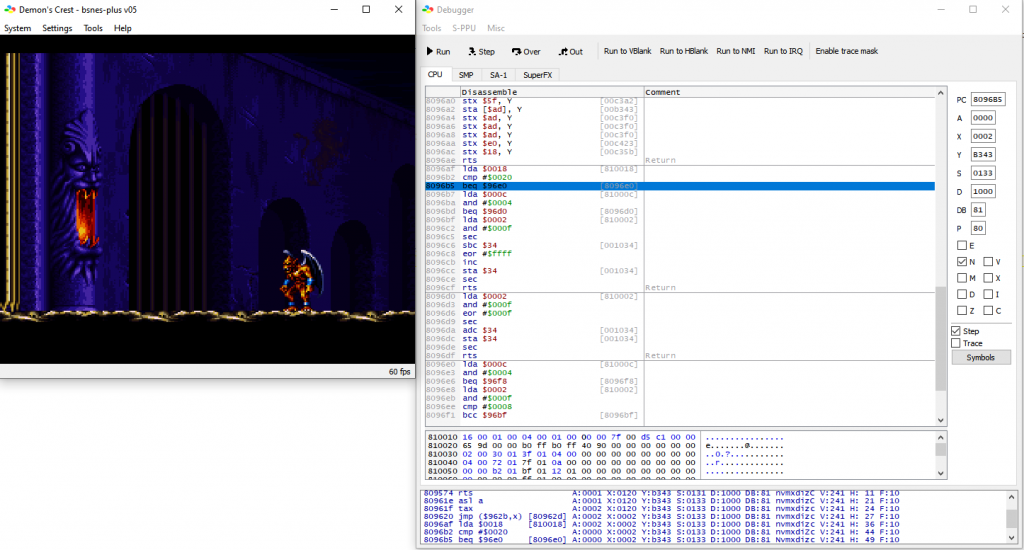
Another example of source-style debugging. The disassembly listing is on the right, with the current instruction highlighted in blue. They go the extra mile and put dividing lines in at observed function boundaries. I don't think that can ever be 100% robust but it's nice regardless.
Or, here's Visual Studio 2019:
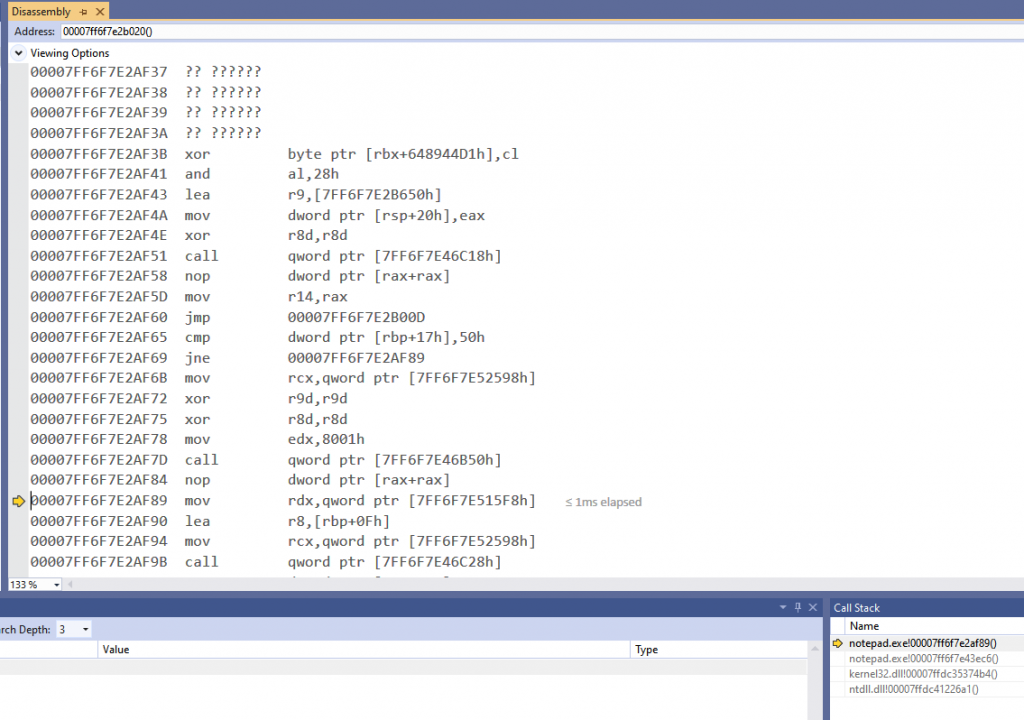
The instructions are listed out. The current instruction is highlighted with a yellow arrow to the left of it. There's some things that couldn't be disassembled so there's a placeholder with question marks.
These are all examples of source-style debugging. It's very popular.
Depending on the implementation, the listing in a source-style debugger can either be
- a local disassembly where all surrounding memory gets interpreted as code, whether it actually is code or not, or
- the result of a tracing, where only executed instructions appear in the listing, creating gaps
The former is a lot more common, as in all the above examples, although I've seen both.
By contrast, a transcript style debugger will look like this:
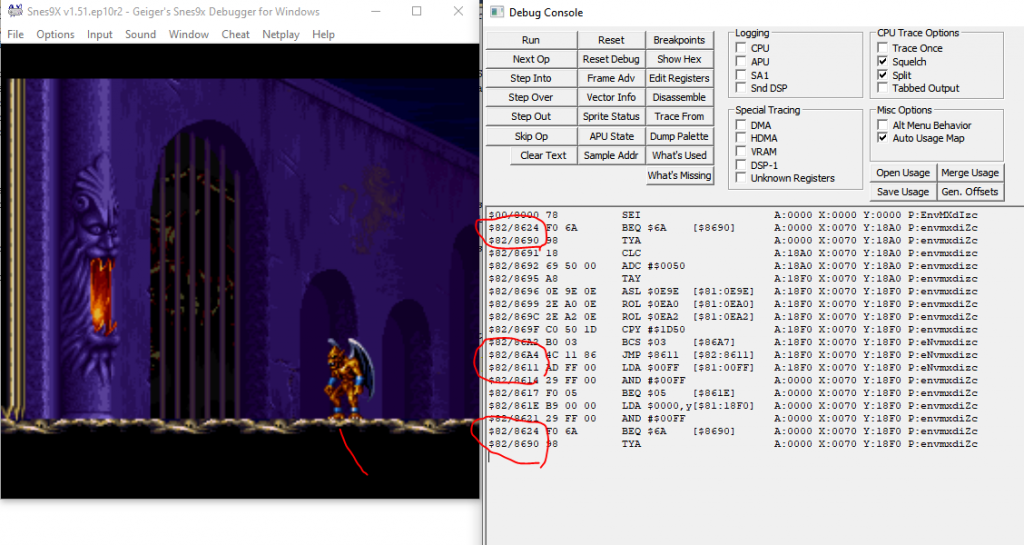
See, there are disjoint instructions, with those pairs circled in red.
Some instructions are listed more than once.
And register state is shown on each line. This platform doesn't have a ton of register space so that's honestly pretty manageable.
The transcript shows all branches with the branch taken, all registers with state at the time, all opcodes with their resolved argument, all loops are unrolled.
The kicker is that implementation of this debugger is dead simple and actually very dumb. It echoes each executed instruction to the output, along with the current register state. That's it.
Yet it is powerful and offers some advantages.
Advantage: history of register values
It's true pretty much all debuggers will show you register values, or variable/memory values at the current instruction. But what about 5 or 10 instructions ago?
You need to either have time-travel debugging, log it, or restart your program.
Some debuggers will cache the "last seen" way something executed (pointer argument, etc), and update it when that instruction is executed again. Great, you can see what was the last way something executed.
But what about the time before that? Or earlier? You can't easily put together a history of what happened unless you log these data points manually yourself.
For reverse-engineering object code with no source code, getting this history is really important in figuring out what happened. You might need to look for trends, look for a pattern, to get a sense of the higher level algorithm. Or you might want transcripts even with code you are familiar with, to get something like a time-travel trace on platforms where actual time-travel isn't available. There's strictly more information in the transcript than in the source-style listing.
"But, it's only outputting registers each line, not all of memory each line". That's true. Each line of the transcript is not a complete state of the machine. I think register state is the right tradeoff to suit most tasks. The exact choice will depend on the platform and the situation. If you're blessed with extensible transcript debugging, that'd probably be the best thing, so you could have like a "watch window" for each line. Generally for SNES, A/X/Y/P is perfectly fine.
Advantage: history of flow control
You can see a clear history of flow control. After all, that's useful. With a couple source-style debuggers, I've seen them do crazy things like try and draw a cute arrow denoting a function was stepped into.
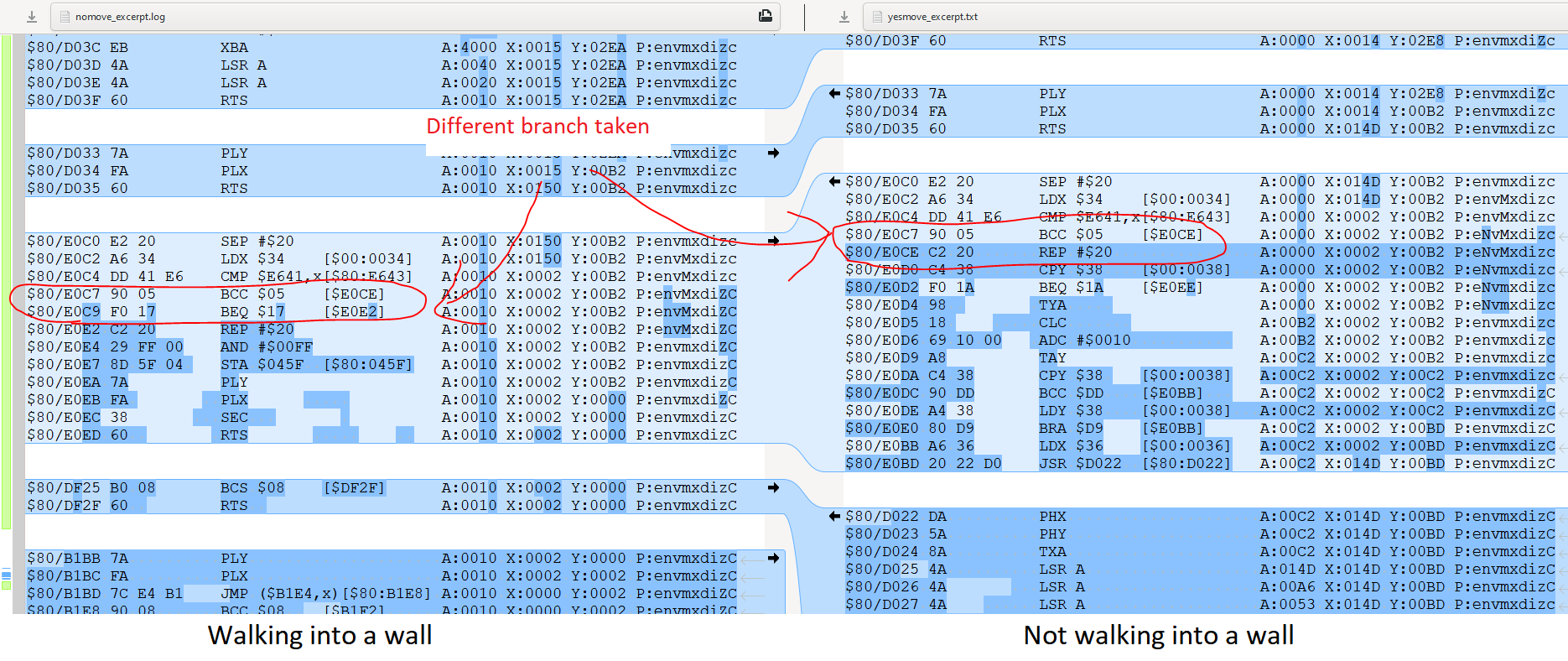
With a transcript, you can see a history of how many times a loop ran, what index of a jump table was used, and which branches had the branch taken. If you save longer transcripts (e.g., with Geiger's SNES debugger's CPU log feature) you can also meaningfully diff transcripts with any text diffing tool of your choice to find divergent control flow like this.
{kind=link}
With source-style debugging, you have no record-keeping of this unless you log it yourself, and you can easily miss what you're looking for.
Advantage: An edge case
This is a bad scenario and not something I've ever seen happen out in the wild.
But you could have it where the same memory is executed twice with the code interpreted in different ways, e.g., 8 bit versus 16 bit native mode.
I don't think a source style debugger could easily make sense of this. A transcript would show what happened clearly.
I made a proof of concept that does this and on testing it doesn't work well at all in a source-style debugger.
Advantage: Don't disassemble stuff that's not code
This is a big one, SNES games will often litter non-code throughout code.
For example of what I mean, consider the game NHL '94 for Super Nintendo, This is bsnes broken in NHL '94's graphics decompression
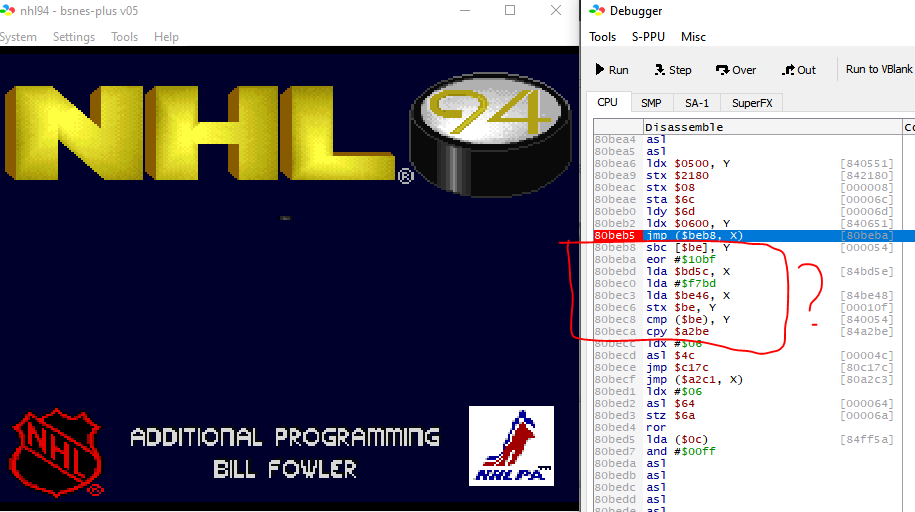
See the part outlined in red. Although there's no obviously illegal instructions, it looks suspicious. Why the CPY with such an arbitrary magic number address? Same with the EOR and the literal, what's up with that? Why the LDAs that immediately get overwritten?
The answer is this isn't code at all. It's data. This source-style debugger will disassemble everything in the neighborhood. That works great only so long as it actually is code. You hope it looks like obvious garbage code, so you can quickly spot it.
In this case, it's actually an array of short pointer offsets baked into the middle of object code. Those are supposed to be offsets, not instructions. If you're really observant you'll see that the preceding JMP $BEB8, X indexes into it and jumps based on an element. It's a hassle to spot this right away, and the debugger isn't doing anything to help you.
Here's another example in a different place
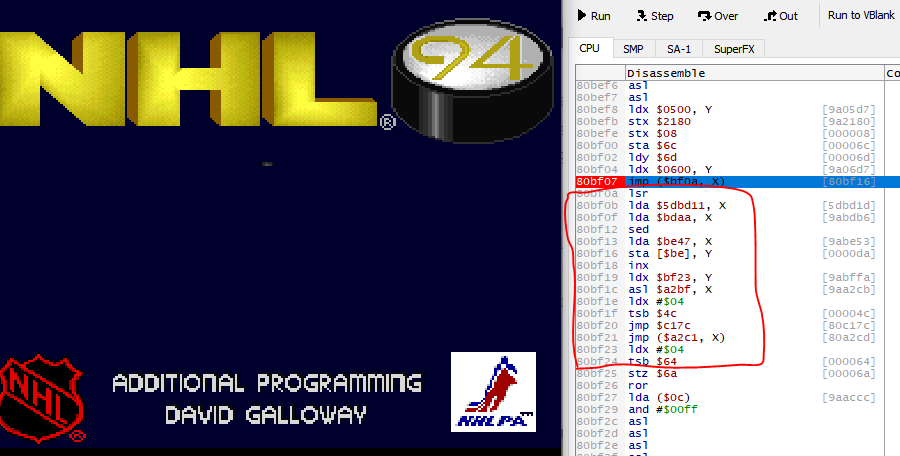
Again red outlined part is not actually code, it's data. This one's sneakier than the above because from a glance it looks less garbage compared to the last one. The big giveaway is SED which is not commonly used.
With transcripts, we don't have this problem. These garbage instructions aren't something you have to discern from non-garbage. Why? Because they don't get executed. They don't even appear.
Why is there data beside the code?
SNES is a different kind of execution environment from what some people are used to.
For the situation above, you might have the reaction "But I work in x86 a lot and I've never seen this before."
Well, x86-64 applications won't have data sprinkled in the code.
Why? Because Intel's architecture does really aggressive instruction prefetching, and the CPU has to know what's code versus what's data for that to work.
You can hear it from Intel themselves:
If (hopefully read-only) data must occur on the same page as code, avoid placing it immediately after an indirect jump. For example, follow an indirect jump with its mostly likely target, and place the data after an unconditional branch.
[...]
Always put code and data on separate pages.
Source: Intel's Optimization Guide
If you write source code that is compiled, at least for a Windows executable, the compiler will put object code in the .text segment and constant data in the .rodata segment- it'll do that for you.
Or if you write source code in x86 assembly language, generally you'd would use a directive like .CODE or .DATA to explicitly define what goes where. The details depend on which assembler you use and what exactly is it outputting.
The WDC 65xx-based CPU, on the other hand, is out there living its best life. Memory is just memory, doesn't matter what's where.
Since it doesn't matter at all, it's up to developer preference and convenience. In practice I do notice developers for 65xx platform dump data in the middle of their code like all the time. They'll bake data local in the same bank to take advantage of direct addressing, since if you put all data together it'd have to go in a different bank to fit. Or they're trying to save a MMU page change on certain computers where that matters (e.g., Foenix F256). Or they'll use a self-modified jump instruction instead of a jump table.
So if you work mostly in x86-64 or any other compiler toolchain with the same recommendation, that's one more reason why you probably go through life dealing with source style debuggers. No surprise data tripping you up. It's probably not something you ever think about.
With reverse-engineering on a platform like SNES the value of transcripts is more clear.
Recommendation
Geiger's SNES debugger is a transcript-style debugger, and you should consider it or something similar if you are debugging SNES without source code.
I also think transcript-style debugging is something we as an industry should consider more for debugging object code without source code. The benefit of source-style assembly debugging really only shines when you have symbolic debugging, or corresponding source code.
Using transcripts liberates you where you're not burdened with mapping control flows back to source code, there is only a series of behaviors. You could map them back to code, eventually. It's just not where you start.
Practical justification: I used transcripts to get these done
- Ripping all maps of Lagoon
- Enlarging the hitboxes in Lagoon
- Making an NHL '94 player name, profile and stats editor
- Making an NHL '94 player graphics decompression tool that's 100% accurate to the game's
- Fixed a bug in Lord of the Rings
- Disabling collisions in Lord of the Rings
- Make plants in Harvest Moon be automatically watered
Bonus: Adding transcripts to C256 Foenix IDE debugger
C256 Foenix is a modern WDC 65816-based computer with an emulator.
For personal convenience I added transcript-style debugging to it, looks like this:
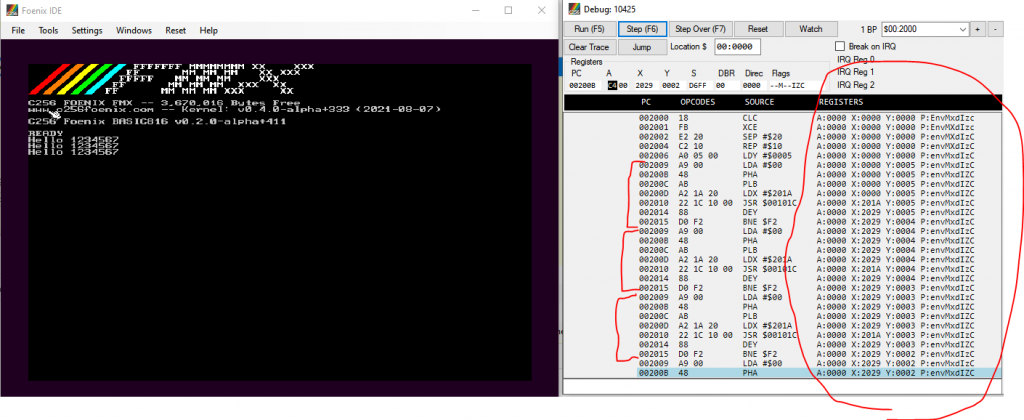
See there's duplicated instructions for a loop, and register output. With source-style, the listing looks like this, which provides a lot less information:

This transcript support is kept side-by-side with the default source-style debugger so that you can switch between them.
Enable it by going to "Settings" and checking the box for "Transcript-style debugger". When the box isn't checked, you get the default source-style debugger. The checkbox setting is remembered like the other settings so you don't need to check it every time.
I've already got some good use out of it. If you want to try it out, it's pushed to this private fork:
https://github.com/clandrew/FoenixIDE/tree/transcript
This change was not accepted for main because it seems like no one else uses this type of debugger, but the private fork is there for my purposes and if you want to use it too.