





Recently someone asked me 'what are HLSL register spaces'? in the context of D3D12. I'm crossposting the answer here in case you also want to know.
A good comparison is C++ namespaces. Obviously, in C++, you can put everything in the default (global) namespace if you want, but having a namespace gives you a different dimension in naming things. You can have two symbols with the same name, and there's some extra syntax you use to help the compiler dis-ambiguate.
HLSL register spaces are like that. Ordinarily, defining two variables to the same register like this:
cbuffer MyVar : register(b0)
{
matrix projection;
};
cbuffer MyVar2 : register(b0)
{
matrix projection2;
};will produce a compiler error, like
1>FXC : error : resource MyVar at register 0 overlaps with resource MyVar2 at register 0, space 0But if you put them in different register spaces, like this:
cbuffer MyVar : register(b0, space0)
{
matrix projection;
};
cbuffer MyVar2 : register(b0, space1)
{
matrix projection2;
};then it’s fine, it's not a conflict anymore.
When you create a binding that goes with the shader register, that’s when you can dis-ambiguate which one you mean:
CD3DX12_DESCRIPTOR_RANGE range;
CD3DX12_ROOT_PARAMETER parameter;
UINT myRegisterSpace = 1;
range.Init(D3D12_DESCRIPTOR_RANGE_TYPE_CBV, 1, 0, myRegisterSpace);
parameter.InitAsDescriptorTable(1, &range, D3D12_SHADER_VISIBILITY_VERTEX);
Q: In the above example, what if I defined both MyVar and MyVar2 as b0, then assigned bindings to both of them (e.g., with SetGraphicsRootDescriptorTable)?
A: That's fine. Just make sure the root parameter is set up to use the register space you intended on.
Small, simple test applications all written by one person usually don’t have a problem with overlapping shader registers.
But things get more complicated when you have different software modules working together. You might have some other component you don’t own, which has its own shaders, and those shaders want to bind variables which occupy shader registers t0-t3. And then there’s a different component you don’t own, which also want t0-t3. Ordinarily, that’d be a conflict you can’t resolve. With register spaces, each component can use a different register space (still a change to their shader code, but a way simpler one) and then there’s no conflict. When you go to create bindings for those shader variables, you just specify which register space you mean.
Another case where register spaces can come in handy is if your application is taking advantage of bindless shader semantics. One way of doing that is: in your HLSL you declare a gigantic resource array. It could be unbounded, or have a very large size. Then at execution time, you populate and use bindings at various indices in the array. Ordinarily, two giant resource arrays would likely overlap each other and create a collision. With register spaces, there's no collision.
Going forward, you might be less inclined to need register spaces with bindless semantics. Why? Because with Shader Model 6.6 dynamic resource indexing, bindless semantics is a lot more convenient- you don't have to declare a giant array. Read more about dynamic resource indexing here: https://microsoft.github.io/DirectX-Specs/d3d/HLSL_SM_6_6_DynamicResources.html
Finally, register spaces can make it easier to port code using previous versions of the Direct3D programming API (e.g., Direct3D 11). In previous versions, applications could use the same shader register to mean different things for different pipeline stages, for example, VS versus PS. In Direct3D 12, a root signature unifies all graphics pipeline bindings and is common to all stages. When porting shader code, therefore, you might choose to use one register space per shader stage, to keep everything correct and non-ambiguous.
If you want some more reference material on register spaces, here's the section of the public spec:
https://microsoft.github.io/DirectX-Specs/d3d/ResourceBinding.html#note-about-register-space
Answer: mostly, yes. Explanation below.
Part 1: Yes or No
Remember GDI? Say you're using GDI and Win32, and you want to draw some graphics to a window. What to do. You read the documentation and see what looks like the most obvious thing: "SetPixel". Sounds good. Takes an x and y and a color. What more could you want? Super easy to use.
But then, you see a bunch of cautionary notes. "It's slow." "It's inefficient." "Don't do it."
Don't do it?
Well. All these cautionary notes you see are from days of yore:
- Computers are faster now. Both CPU and GPU. Take an early CS algorithms class, experiment with solutions. You’ll see sometimes the biggest optimization you can do is to get a faster computer.
- An earlier Windows graphics driver model. Say, XPDM not WDDM. WDDM means all hardware-accelerated graphics communicate through a “Direct3D-centric driver model”, and yes that includes GDI. Changes in driver model can impose changes in performance characteristics.
- Different Windows presentation model. That's something this API is set up to negotiate with, so it could affect performance too. Nowadays you're probably using DWM. DWM was introduced with Windows Vista.
The date stamps give you skepticism. Is that old advice still true?
As a personal aside, I've definitely seen performance advice from people on dev forums that is super outdated and people get mis-led into following it anyway. For example for writing C++ code, to "manually turn your giant switch case into a jump table". I see jump tables in my generated code after compilation... The advice was outdated because of how much compilers have improved. I've noticed a tendency to trust performance advice "just in case", without testing to see if it matters.
Let us run some tests to see if SetPixel is still slow.
I wrote a benchmark program to compare
- SetPixel, plotting each pixel of a window sequentially one by one, against
- SetDIBits, where all pixels of a window are set from memory at once.
In each case the target is a top-level window, comparing like sizes. Each mode effectively clears the window. The window is cleared to a different color each time, so you have some confidence it’s actually working.
Timing uses good old QPC. For the sizes of timespans involved, it was not necessary to get something more accurate. The timed interval includes all the GDI commands needed to see the clear on the target, so for SetDIBits that includes one extra BitBlt from a memory bitmap to the target to keep things fair.
The source code of this benchmark is here.
Here are the results
| Width | Height | Pixel Count | SetPixel | SetDIBits |
| 1000 | 1000 | 1000000 | 4.96194 | 0.0048658 |
| 950 | 950 | 902500 | 4.7488 | 0.0042761 |
| 900 | 900 | 810000 | 4.22436 | 0.0038637 |
| 850 | 850 | 722500 | 3.71547 | 0.0034435 |
| 800 | 800 | 640000 | 3.34327 | 0.0030824 |
| 750 | 750 | 562500 | 2.92991 | 0.0026711 |
| 700 | 700 | 490000 | 2.56865 | 0.0023415 |
| 650 | 650 | 422500 | 2.21742 | 0.0022196 |
| 600 | 600 | 360000 | 1.83416 | 0.0017374 |
| 550 | 550 | 302500 | 1.57133 | 0.0015125 |
| 500 | 500 | 250000 | 1.29894 | 0.001311 |
| 450 | 450 | 202500 | 1.05838 | 0.0010062 |
| 400 | 400 | 160000 | 0.826351 | 0.0009907 |
| 350 | 350 | 122500 | 0.641522 | 0.0006527 |
| 300 | 300 | 90000 | 0.467687 | 0.0004657 |
| 250 | 250 | 62500 | 0.327808 | 0.0003364 |
| 200 | 200 | 40000 | 0.21523 | 0.0002422 |
| 150 | 150 | 22500 | 0.118702 | 0.0001515 |
| 100 | 100 | 10000 | 0.0542065 | 9.37E-05 |
| 75 | 75 | 5625 | 0.0315026 | 0.000122 |
| 50 | 50 | 2500 | 0.0143235 | 6.17E-05 |
Viewed as a graph:
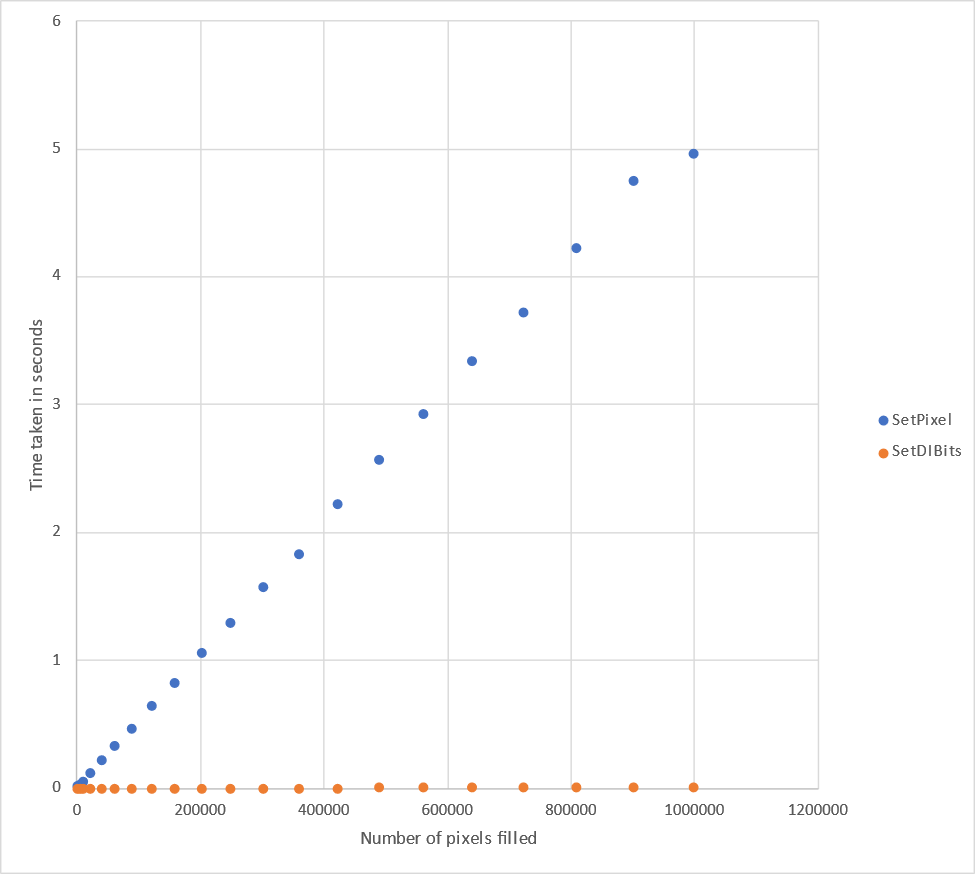
Conclusion: yeah, SetDIBits is still way faster than SetPixel in general, in all cases.
For small numbers of pixels, the difference doesn't matter as much. For setting lots of pixels, the difference is a lot.
I tested this on an Intel Core i7-10700K, with {NVIDIA GeForce 1070 and WARP} with all similar results.
So the old advice is still true. Don't use SetPixel, especially if you’re setting a lot of pixels. Use something else like SetDIBits instead.
Part 2: Why
My benchmark told me that it’s still slow, but the next question I had was ‘why’. I took a closer look and did some more thinking about why it could be.
It's not one reason. There's multiple reasons.
1. There's no DDI for SetPixel.
You can take a look through the public documentation for display devices interfaces, and see what’s there. Or, take a stab at it and use the Windows Driver Kit and the provided documentation to write a display driver yourself. You’ll see what’s there. You’ll see various things. You’ll see various blit-related functions in winddi.h. For example, DrvBitBlt:
BOOL DrvBitBlt(
[in, out] SURFOBJ *psoTrg,
[in, optional] SURFOBJ *psoSrc,
[in, optional] SURFOBJ *psoMask,
[in] CLIPOBJ *pco,
[in, optional] XLATEOBJ *pxlo,
[in] RECTL *prclTrg,
[in, optional] POINTL *pptlSrc,
[in, optional] POINTL *pptlMask,
[in, optional] BRUSHOBJ *pbo,
[in, optional] POINTL *pptlBrush,
[in] ROP4 rop4
);That said, you may also notice what’s not there. In particular, there’s no DDI for SetPixel. Nothing simple like that, which takes an x, y, and color. It’s important to relate this to the diagrams on the “Graphics APIs in Windows” article, which shows that GDI talks to the driver for both XPDM and WDDM. It shows that every time you call SetPixel, then what the driver sees is actually far richer than that. It would get told about a brush, a mask, a clip. It’s easy to imagine a cost to formulating all of those, since they you don’t specify them at the API level and the API is structured so they can be arbitrary.
2. Cost of talking to the presentation model
There’s a maybe-interesting experiment you can do. Write a Win32 application with your usual WM_PAINT handler. Run the application. Hide the window behind other windows, then reveal it once again. Does your paint handler get called? To reveal the newly-revealed area? No, normally it doesn’t.
So what that must logically mean is that Windows kept some kind of buffer, or copy of your window contents somewhere. Seems like a good idea if you think about it. Would you really want moving windows around to be executing everyone’s paint handlers all the time, including yours? Probably not. It’s the good old perf-memory tradeoff in favor of perf, and it seems worth it.
Given that you’re drawing to an intermediate buffer, then there’s still an extra step needed in copying this intermediate buffer to the final target. Which parts should be copied, and when? It seems wasteful to be copying everything all the time. To know what needs to get re-copied, logically there has to be some notion of an “update” region, or a “dirty” region.
If you’re an application, you might even want to aggressively optimize and only paint the update region. Can you do that? At least at one point, yes you could. The update region gets communicated to the application through WM_PAINT- see the article “Redrawing in the Update Region”. There’s a code example of clipping accordingly. Now, when I tried things out in my application I noticed that PAINTSTRUCT::rcPaint is always the full window, even in response to a small region invalidated with InvalidateRect, but the idea is at least formalized in the API there.
Still, there’s a cost to dealing with update regions. If you change one pixel, that one-pixel area is part of the update region. Change the pixel next to it, the region needs to be updated again. And so on. Could we have gotten away with having a bigger, coarser update region? Maybe. You just never know that at the time.
If you had some way of pre-declaring which regions of the window you’re going to change, (e.g., through a different API like BitBlt), then you wouldn’t have this problem.
3. Advancements in the presentation model help, but not enough
In Windows, there is DWM- the Desktop Window Manager. This went out with Windows Vista and brought about all kinds of performance improvements and opportunity for visual enhancements.
Like the documentation says, DWM makes it possible to remove level of indirection (copying) when drawing contents of Windows.
But it doesn’t negate the fact that there still is tracking of update regions, and all the costs associated with that.
4. Advancements in driver model help, but not enough
DWM and Direct3D, as components that talk to the driver through the 3D stack, have a notion of “frames” and a particular time at which work is “flushed” to the GPU device.
By contrast, GDI doesn’t have the concept of “frames” or flushing anything. Closest thing would be the release of the GDI device context, but that’s not strictly treated as a sign to flush. You can see it yourself in how your Win32 GDI applications are structured. You draw in response to WM_PAINT. Yes there is EndPaint, but EndPaint doesn’t flush your stuff. Try it if you want- comment out EndPaint. I tried it just to check and everything still works without it.
Since there isn’t a strict notion of “flushing to the device”, SetPixel pixels have to be dispatched basically immediately rather than batched up.
5. 3D acceleration helps, but not enough
Nowadays, GDI blits are indeed 3D accelerated.
- They were,
- then they weren’t for Vista,
- then they were again.
I noticed this firsthand, too. Very lazy way to check- in the “Performance” tab in Task manager when I was testing my application, I saw little blips in the 3D queue. These coincided with activity in the SetPixel micro-benchmark.
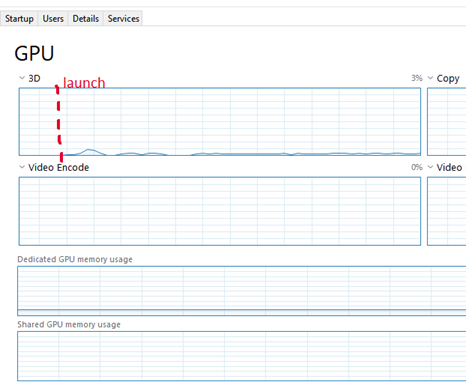
Again, very lazy check. Good to know we are still accelerating these 2D blits, even as the graphics stack has advanced to a point of making 3D graphics a first-class citizen. Hardware acceleration is great for a lot of things, like copying large amounts of memory around at once, applying compression or decompression, or manipulating data in other ways that lend itself to data-parallelism.
Unfortunately, literally none of that helps this scenario. Parallelism? How? At a given time, the driver doesn’t know if you’re done plotting or what you will plot next or where. And it can’t buffer up the operations and execute them together, because it, like Windows, doesn’t know when you’re done. Maybe, it could use some heuristic.
But that brings this to the punchline: even if the driver had psychic powers, it could see into the future and know exactly what the application is going to do and did an absolutely perfect job of coalescing neighboring blits together, it doesn’t negate any of the above costs, especially 1. and 2.
Conclusion
Even in the current year, don’t use SetPixel for more than a handful of pixels. There’s reasons to believe the sources of the bottlenecks to have changed over 30 years, yet even still the result is the same. It’s slow and the old advice is still true.
Epilogue: some fantasy world
This post was about how things are. But, what could be? What would it take for SetPixel not to be slow? The most tempting way to think about this is to flatten or punch holes through the software stack. That works, even if it feels like a cop-out.
Suppose you have a Win32 program with a checkbox. You just added it. No changes to message handler.
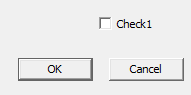
You click the box. What happens?
Answer: the box appears checked. Click it again, the box becomes un-checked. Riveting
Now suppose you have a Win32 menu item that is checkable. Again, added with no changes to message handler.
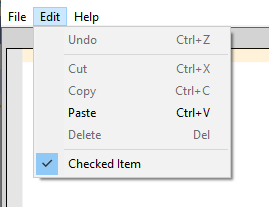
You click the item. What happens?
Answer: Nothing. It stays checked, if it was initialized that way. Unchecked, if it was initialized that way.
In both these cases, the item was added straightforwardly through resource script with no changes to the message handler.
Why are these two things different?
Explanation: apparently it falls out of broader Win32 design. The automatic-ness that the normal checkbox has, requires features to control it. For example, those checkboxes can be grouped into radio button groups with WS_GROUP. To add that same richness to menu items, too? You could, but it'd be an increase in complexity, and the benefit would need to be clearly justified. There'd need to be an "MF_GROUP" and all the API glue that comes cascading with it. Also, automatic checkbox-ness brings with it the chance of encountering errors, and errors tends to mean modal dialogs. It's okay to launch dialogs during normal window interactions, that happens all the time. But from a menu item? It would be really jarring and unexpected. Going more broadly than that it runs the risk of encouraging of bad habits: you might use the hypothetical "MF_GROUP" glue to do something strange and expensive, and that's not what menu items are for. Since it's not clear the benefit is justified, you're on your own for check state.
In case you were wondering, I'm not really trying to "sell" this inconsistency to you. I was just as surprised as you were. I am trying to explain it based on sources though. It's not random.
Something related- this docpage, "Using Menus - Simulating Check Boxes in a Menu". The sample code leaves you asking some broader questions of "why am I doing all this?"
Raymond Chen article fills in blanks: "Why can't you use the space bar to select check box and radio button elements from a menu?"
The design is also conveyed through Petzold's "Programming Windows, 5th edition" page 445 in the code sample "MENUDEMO.C". The message handler goes like
case IDM_BKGND_WHITE: // Note: Logic below
case IDM_BKGND_LTGRAY: // assumes that IDM_WHITE
case IDM_BKGND_GRAY: // through IDM_BLACK are
case IDM_BKGND_DKGRAY: // consecutive numbers in
case IDM_BKGND_BLACK: // the order shown here.
CheckMenuItem (hMenu, iSelection, MF_UNCHECKED) ;
iSelection = LOWORD (wParam) ;
CheckMenuItem (hMenu, iSelection, MF_CHECKED) ;The general trend in this book is to leverage automatic facilities in the Win32 API wherever it makes sense to do. But here, the radio button-ness is all programmatic for checkable menus.

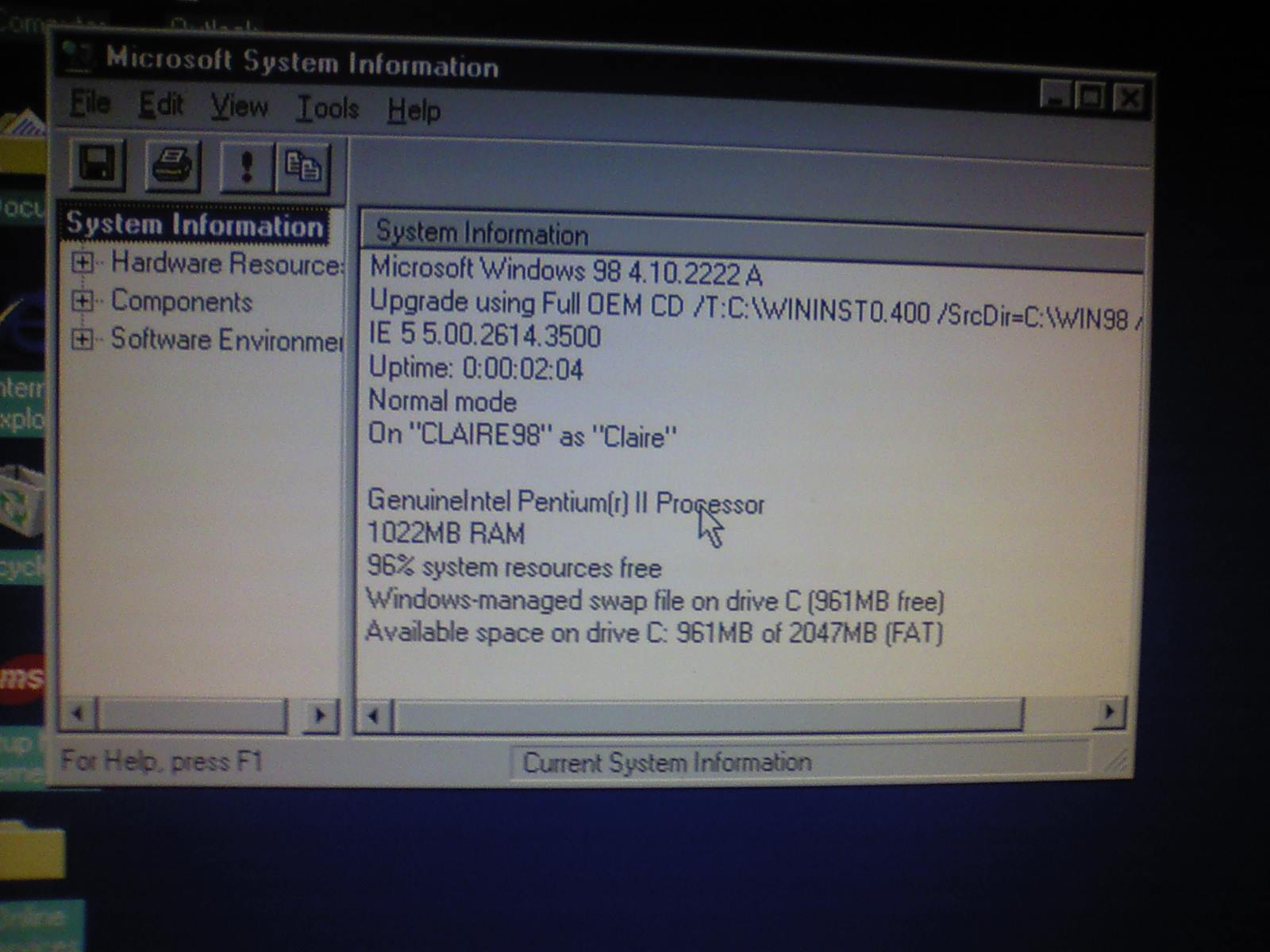
I installed Windows 98 to the "space heater computer"
Is it possible to install 98 to an Intel Core-i5 with 4GB of DDR3 RAM?
Turns out, yes. If you spoof it to only enumerate 1GB, plus a bunch of other sketchy edits to system.ini and config.sys.
Got all size+speed optimization challenges in Human Resource Machine!
Some of them are HARD.
I have new appreciation for being able to std::swap (in one expression), or use, like, any literals
And the ending. The reward is a creepy cutscene...





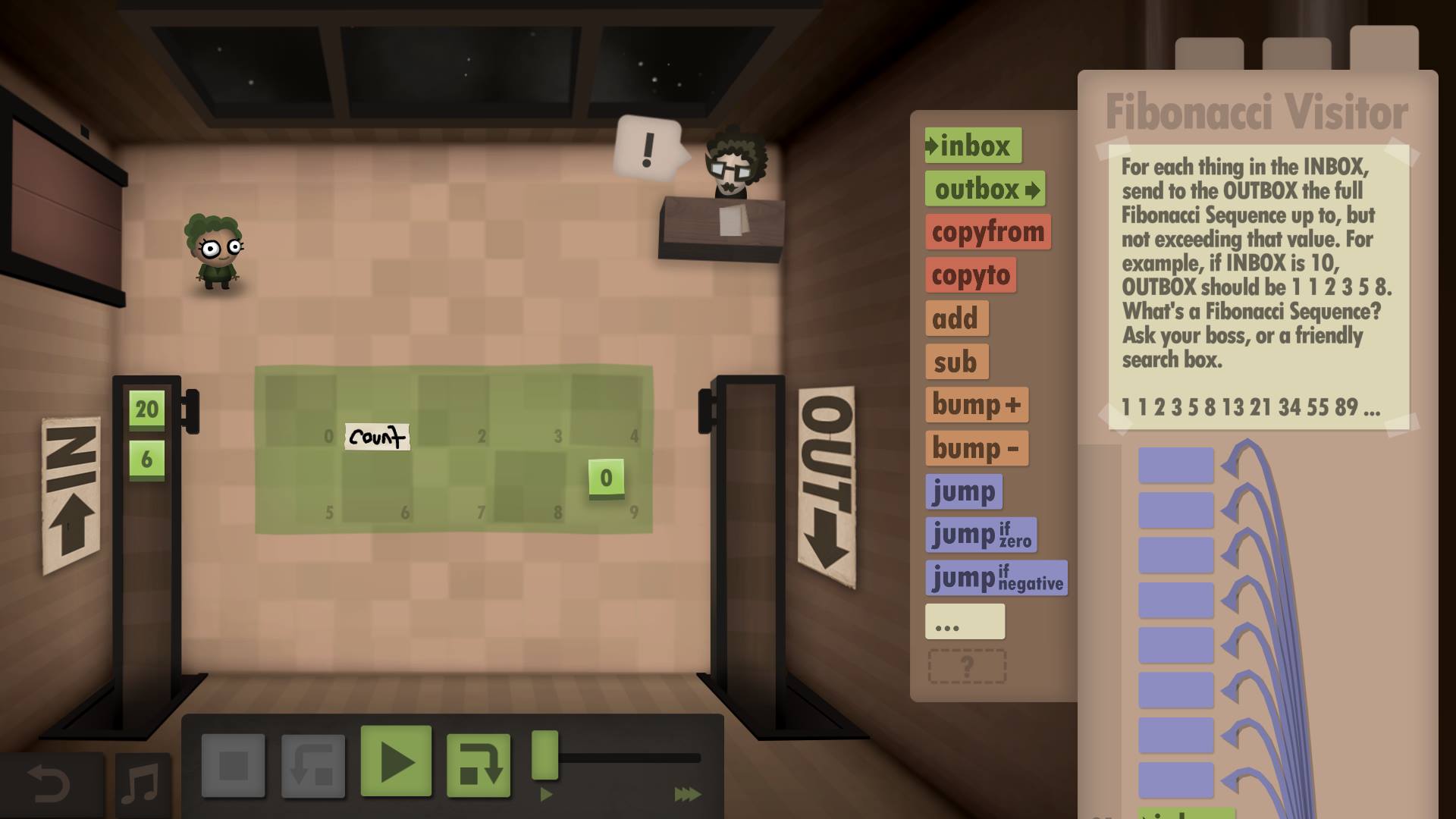
A task in Human Resource Machine.
The idea is to write a program that computes Fibbonacci numbers; the program is comprised of simple assembly-like instructions. The game gives you special bonuses for optimizing for speed or size.
This approach uses loop unrolling. The resulting program is really unwieldy and cumbersome to follow, but outperforms the speed goal by a lot.


Finally, I get to share this out! This is PIX, something I've helped build. Debug+profile ALL the DirectX12 games.
Finished Braid for the first time.
The levels are really clever. Got all the puzzle pieces, got the ending/epilogue, and was left really confused.
What the heck is going on! I understand 0% of the lore of this game.