





Do you remember DirectDraw? The DirectX 5 SDK disc came with a bunch of samples, including one called "Wormhole".
Looks like this:
How it works: despite how the image looks animated, there's no change to the framebuffer data. It's all palette rotation. The sample comes with a bitmap specially chosen so that the colors rotate to produce this 'wormhole' animation.
If you want to try it yourself, load it up from a DirectX 5 SDK disc (it's on some other SDK version discs, as well). Or, you can find it on the Internet Archive here: https://archive.org/details/idx5sdk.
My project: ported this sample to C256 Foenix. (Update: I later also ported it to F256 Foenix.)
This is a language (C to 65816) and platform (Win32+DirectDraw to C256 Foenix + Vicky II) port.
Some of the challenges were:
- Making sure the right bitmap with the right palette gets initialized. See, it's not sufficient to simply read RGB of the original bitmap and emit a new one that looks visually equivalent. The original bitmap's palette needs to be preserved. It contains "dead" colors- colors that aren't referenced by any one pixel as you view it, but are important to the rotation effect. I wrote a tool called BitmapEmbedder to take care of this.
- Betting on how long, in terms of clock, the rotation effect would take to execute. I was bold and put it all in VBLANK handler. Fortunately it fit and I didn't optimize for perf super aggressively. I had no idea whether it would fit. If it didn't, I would've to pull a bunch of it out and synchronize it. And it would be easier to do that at the beginning, before it's all set up. I took the risk at the beginning that it would fit and this paid off.
- Having a loop that needed to be longer than the signed branch distance limit. I could have maybe added a "hop" to get back to the beginning of the loop. Instead I factored out a function for no reason other than to get past the limit. It doesn't make me feel great. Could be something to revisit later.
A bunch of other things worked well. Vicky II has a dedicated bitmap layer that you can cleanly copy to. I say cleanly because it was a lot easier to work with compared to Apple II, and SNES for that matter. There isn't any weird swizzling, interleaving or holes. It was exactly compatible with a DirectDraw surface in terms of indexed color and surface size.
Result looks like: (comparison between the original and the port)
If you aren't familiar with the concept of palette rotation:
Palette rotation is a visual effect made possible by storing image data in a compact way.
You might be familiar with not-very-compact ways to store image data. For each pixel, say, you store a red, green and blue color value. Functionally that works, no worries. But the memory cost- even if each color channel is only two-thirds of a byte, then each pixel will still take up two bytes. Or if each color channel is a byte, you're looking at three bytes then. Or even four if you use alpha. The memory cost can really add up to more than you can afford.
There's a more compact way to store image data. You can store indexed color instead. For each pixel, store a key. The key is only 1 byte, not 4. It's a number from 0 to 255. When the computer displays the image on the screen, it will use that key to look up into a palette, or table of colors. In a way, this limits image quality, since you can only have an image with a low total number of colors (256). But you save a lot of memory. After all, each pixel takes up only one byte.
There are different configurations of key size affecting how many colors you can use at a time. You could sacrifice image quality to optimize for memory even more. Like anything there are tradeoffs. Having a key be one byte is a popular choice though, and this is supported on Vicky II.
Ordinarily, it'd cost a lot of perf to implement palette lookups yourself in your software code. "For each pixel, look up into the palette, assign a color..." It's be so slow. Fortunately, indexed color is an industry-recognized idea that has built-in hardware acceleration on a ton of platforms, including on Vicky II. That's where the benefit really shines, so you don't have to worry.
Anyway, as you see with indexed color, there's indirection. Change one entry in the palette, a simple one-byte change, and it could affect half your image or more. Because of the indirection used with indexed color, an effective way to animate things can be to not animate the image data at all, but to simply make a small change to the palette. The palette has way fewer bytes of data, yet the capacity to change how the whole image looks.
Palette rotation can also be called color cycling. There are some beautiful artworks using color cycling to convey water, snow, or other effects. For example, see this snow effect from this demo page (not my page):
The grid in the lower right shows the palette being changed.
Or this one, with rain:
The Wormhole sample uses the idea of palette rotation to achieve an animation effect. It only copies the original bitmap data once on application start. It never touches it again.
Every VBLANK handler, it only updates the palette. And although it does a lot of manipulations to the palette-- there's four loops, iterating over various parts of it, copying entries around-- it can still be way less expensive than an alternative way of animating things- iterating over every pixel in the bitmap. This way, you can exploit this compactness in the image format to get a performance benefit too.
Source code available here:
https://github.com/clandrew/wormhole/blob/main/vickyii/wormhole.s
Consider this 65816 program
.cpu "65816"
PUTS = $00101C
PUTC = $001018
* = $00FFFC
RESET .word <>START
* = $002000
START CLC ; Make sure we're native mode
XCE
REP #$30
.al
.xl
JSR MSG1
SEP #$30 ; Set 8bit axy
DIV
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; Value ; 8bit interpretation ; 16bit interpretation
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
; ; ;
.byte $A9 ; LDA #$3A ; LDA #$3A3A
.byte $3A ; ;
.byte $3A ; DEC A ;
; ; ;
.byte $29 ; AND #$39 ; AND #$3A39
.byte $39 ; ;
; ; ;
.byte $3A ; DEC A ;
; ; ;
.byte $29 ; AND #$38 ; AND #$2038
.byte $38 ; ;
; ; ;
.byte $20 ; JSR $20EA ;
.byte $EA ; ; NOP
; ; ;
.byte $20 ; ; JSR $20E0
; ; ;
.byte $E0 ;
.byte $20 ;
TAX
JSR CLRB
JSL PUTS
JSR MSG2
DONE NOP ; Spin
BRA DONE
* = $002038
MODE16 .null "16"
PRE .null "This is in "
SUF .null "-bit mode. "
CLRB LDA #$0000
PHA
PLB
PLB
RTS
MSG1 JSR CLRB
LDX #<>PRE
JSL PUTS
RTS
MSG2 JSR CLRB
LDX #<>SUF
JSL PUTS
RTS
* = $0020E0
RTS
* = $0020EA
JSL PUTC
REP #$30
.al
.xl
JSR MSG2
JSR MSG1
JMP DIVfor C256 Foenix, assembled with 64tass.
When run, the output looks like
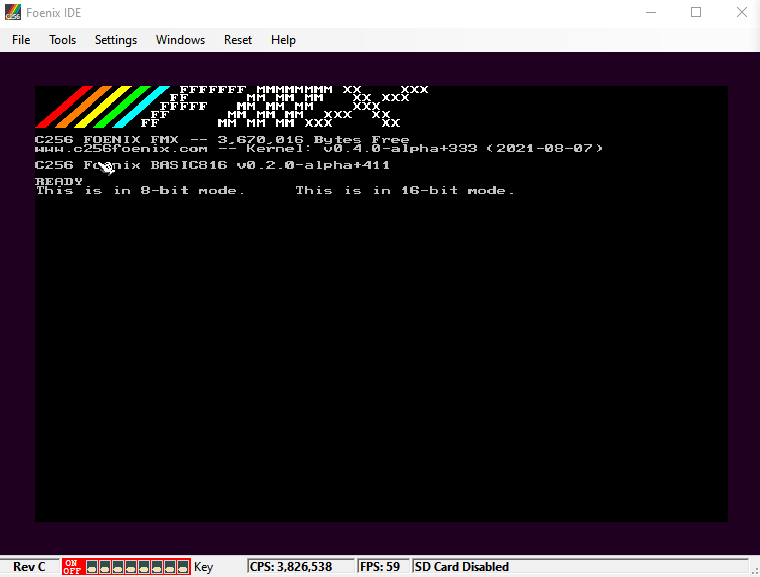
Explanation: the part of the program labeled 'DIV' will run twice, under different interpretations. First in 8bit mode, then in 16bit mode, for displaying the '8' and '16' printable characters respectively.
Normally code in 8bit is garbage when interpreted in 16bit mode and vice-versa. These ops were specially chosen so that they are valid in both with different behavior
Because it's not possible to express the reinterpretation idea in an assembly language, this just dumps the code bytes in the middle of the program and there's 2 columns of commented-out language explaining what the bytes do. The 2 columns are one for 8bit and one for 16bit.
I wrote it as a silly test. It's a test for the debugger. It's to see how it might display in a 'source-style' debugger. When running it I pass the debugger my source file listing.
It goes... not great
'Transcript debugging' described in this earlier post fixes it, it's 100% coherent and matches the source.
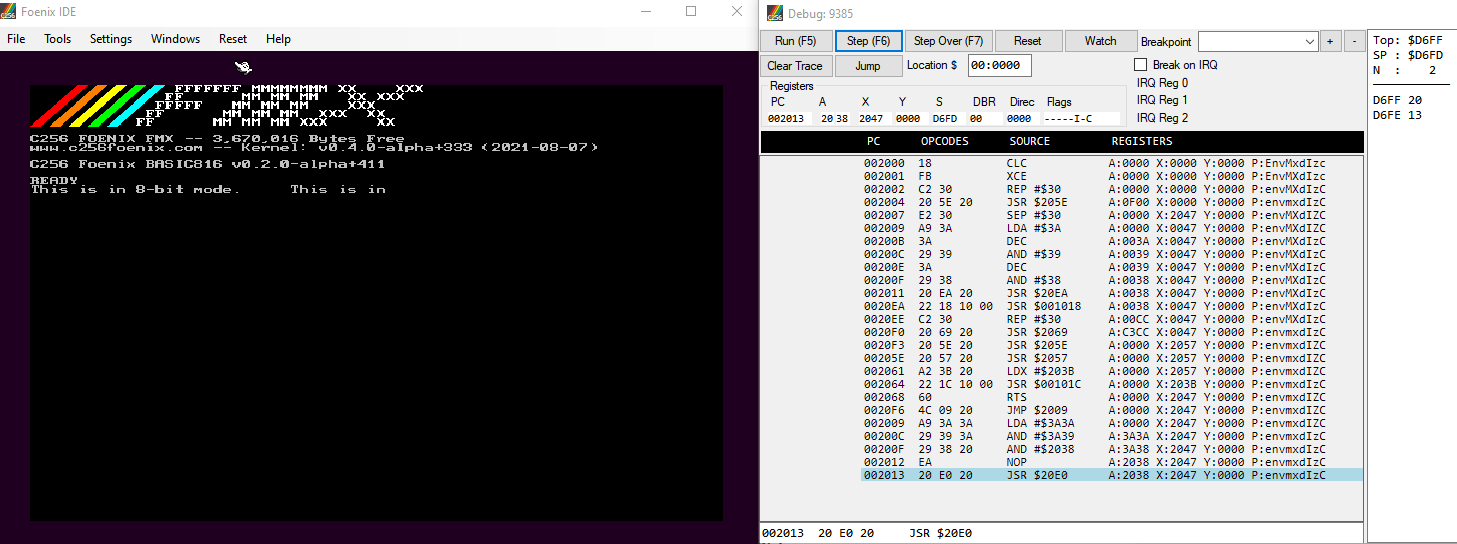
So a good vote to use that kind of debugger for this type of thing.
Full source code available here:
Summary: I'm making a case for a certain type of debugger.
More detail below.
A couple times people trying to get into ROM patching ask me what tool I use. I'll answer, although it's not the popular answer. It takes some getting used to because of type of debugging it is and for other reasons.
What I use for most of my patching stuff is Geiger's SNES debugger. It's a special build of Snes9x with a debugger bolted on.
Looks like this
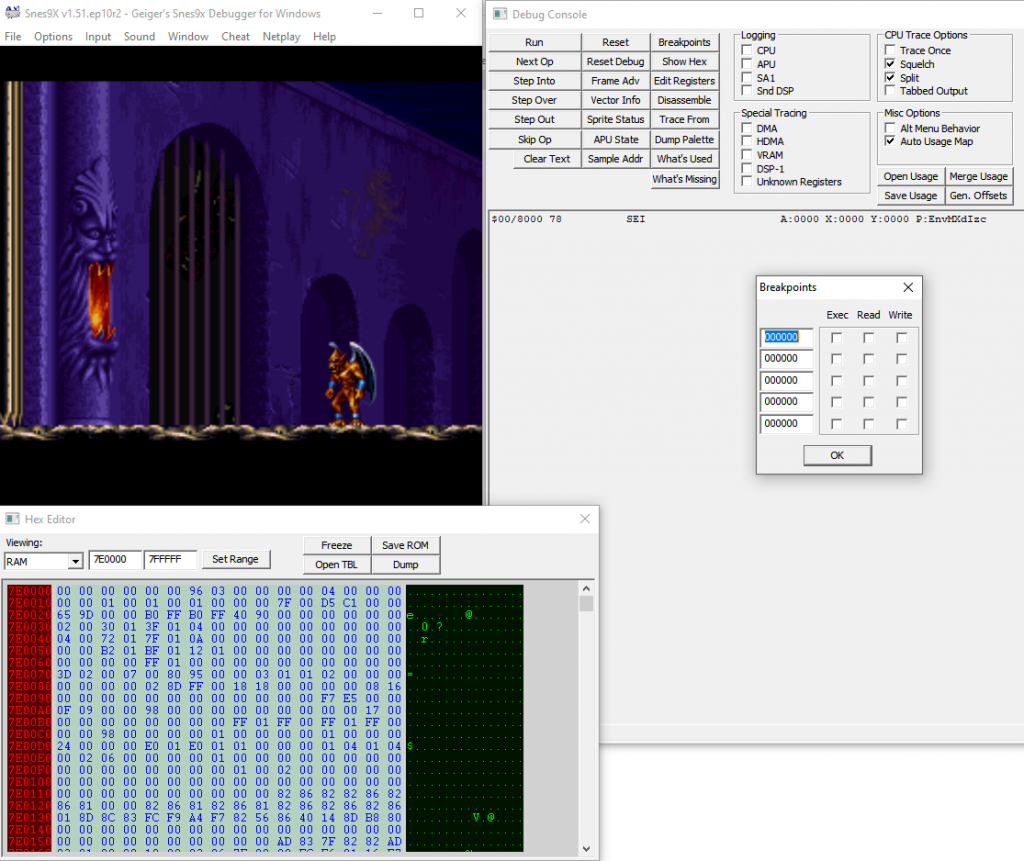
The game, main debugger interface, and memory view are in different windows. You press the 'Breakpoints' button to get a pop-up dialog for setting those. Looks very Win32 ish.
Why not for everyone?
When I first started looking into debugging SNES it was a while ago, this was one of the best options available.
Since then, the world has moved on.
Despite the age of the SNES today, there is a lot of information out there sourced by fans and tools under active development.
Today, there are SNES debuggers that
- have larger feature sets
- have been tested more thoroughly to weed out issues
- have interfaces that suit newer UI/UX paradigms
- are actively developed
- are open-source and so are easy to extend
The debugger has some 'personality traits' I've gotten used to working around. Here's a list of what they are in case you run into them.
Issue: Breakpoints don't hit after certain operations (e.g., save state load)
Workaround: Re-open the breakpoint window, and click OK.
Issue: Step Out doesn't step out to the expected place
Workaround: Don't rely on Step Out for function calls that straddle any interrupts.
Issue: 'Show Hex' (memory) window shows blank ROM on 1st open
Workaround: Choose something (e.g., RAM) 'viewing' dropdown then go back to ROM.
Issue: Emulator crash if you scroll too far down in the memory window
Workaround: Don't use invalid ranges. Don't try to scroll past the end of the range.
Issue: Can not view CGRAM or OAM
Workaround: Use a different debugger.
Issue: Can not view DBR or PBR
Workaround: Edit some code to push them (PHB/PHK) then PLA.
Software
The debugger isn't under active development anymore so things like the above list are what they are. I contacted Geiger asking for the source code. He responded wishing me well, and wouldn't give it to me for various reasons which is his perogative.
None of these were bad enough to block me, it's been alright.
They also weren't severe enough to be motivating to go in and fix them in this closed-source program.
Why I use it
Despite the above things, I still use it for a few reasons.
- Habit. I know my way around it
- The most complicated parts of what I need to do aren't actually through a debugger, (e.g., 'special diffing' of memory dumps), and a debugger could never do as good a job as flexible-function code.
- Transcript-style debugging.
The biggest one is transcript debugging.
For transcript-style debugging see explanation below.
Transcript-style debugging
For ROM patching projects where the patch is a small targeted surface area, generally speaking you're not trying to recover source code.
Recovering source code so that you can work in it is something you can do if you really want. You can do it if it makes you happy. But it's not always crucial. It can even be a distraction. Be it in an assembly language or a higher-level language like C/C++, recovering source code can be unnecessary for your goal of a targeted change in behavior and can make the task way less efficient.
To get better at this kind of reverse-engineering task, and this is hard for a lot of people to hear-- you need to fall out of love with source code written in programming languages. This includes source-level debugging, it includes expressions of flow control, and this includes source code written in assembly languages.
Below is an example of a debugger listing not using source-level debugging, and using transcript-style debugging instead:
$80/BC3A 20 B0 C1 JSR $C1B0 [$80:C1B0] A:0000 X:00A9 Y:0005 P:envmXdizc
$80/C1B0 64 6F STZ $6F [$00:006F] A:0000 X:00A9 Y:0005 P:envmXdizc
$80/C1B2 A5 6C LDA $6C [$00:006C] A:0000 X:00A9 Y:0005 P:envmXdizc
$80/C1B4 0A ASL A A:3640 X:00A9 Y:0005 P:envmXdizc
$80/C1B5 88 DEY A:6C80 X:00A9 Y:0005 P:envmXdizc
$80/C1B6 F0 13 BEQ $13 [$C1CB] A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1B8 90 38 BCC $38 [$C1F2] A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1F2 86 00 STX $00 [$00:0000] A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1F4 A2 02 LDX #$02 A:6C80 X:00A9 Y:0004 P:envmXdizc
$80/C1F6 0A ASL A A:6C80 X:0002 Y:0004 P:envmXdizc
$80/C1F7 88 DEY A:D900 X:0002 Y:0004 P:eNvmXdizc
$80/C1F8 F0 20 BEQ $20 [$C21A] A:D900 X:0002 Y:0003 P:envmXdizc
$80/C1FA E8 INX A:D900 X:0002 Y:0003 P:envmXdizc
$80/C1FB 90 F9 BCC $F9 [$C1F6] A:D900 X:0003 Y:0003 P:envmXdizc
$80/C1F6 0A ASL A A:D900 X:0003 Y:0003 P:envmXdizc
$80/C1F7 88 DEY A:B200 X:0003 Y:0003 P:eNvmXdizC
$80/C1F8 F0 20 BEQ $20 [$C21A] A:B200 X:0003 Y:0002 P:envmXdizC"But isn't this source code in assembly language?" I heard this question before. I think this confusion comes from people who haven't done much forward engineering with assembly languages yet, forget reverse engineering.
The above is not source code, it's a debugger transcript.
Again, it's not source code, it's printout of what got executed, one instruction at a time.
Dead giveaways that it's not source code
- Every line starts with an address
- Every line ends with register state
- There's a function call and then the stepped-into body immediately after. Not proper for source code
- Some instructions are repeated, like $80/C1F6, $80/C1F7, $80/C1F8. This is a loop
Thinking it's source code is pretty uncharitable to the readability of source code, which usually uses more identifiers and comments and labels and stuff than this example has.
The transcript looks different from source code, and transcript debugging is different from source style debugging.
How is transcript debugging different?
Now that we know what transcripts are: transcript-style debugging is different from source-style, or traditional debugging.
See an example of source-style debugging, with No$sns:
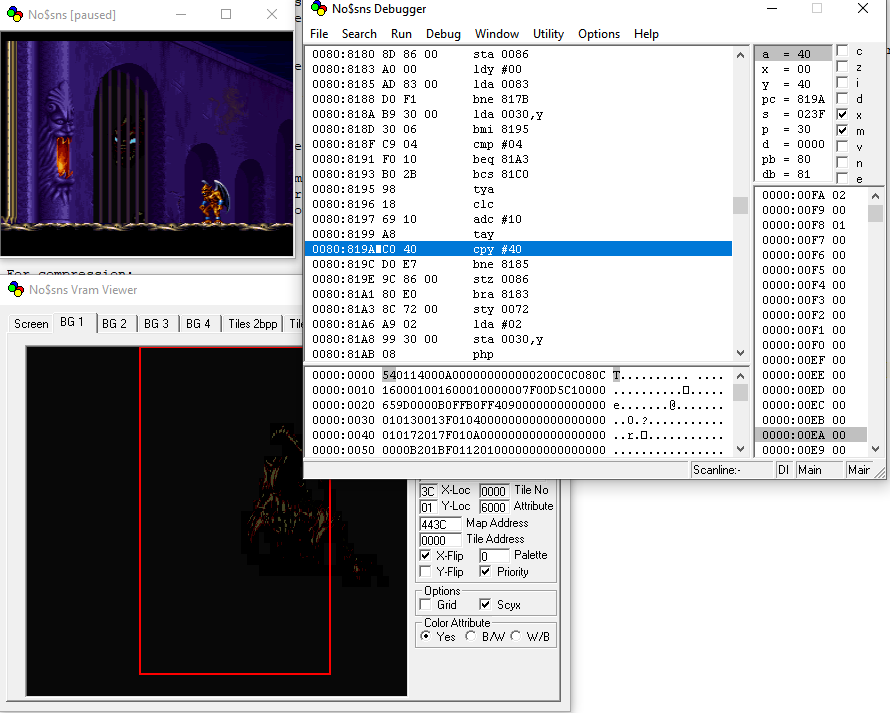
There's a window. In the window, the local disassembly appears in a listing, with the current instruction highlighted in blue. The local disassembly shows instructions laid out in one contiguous block of memory.
Or, here's another debugger, bsnes:
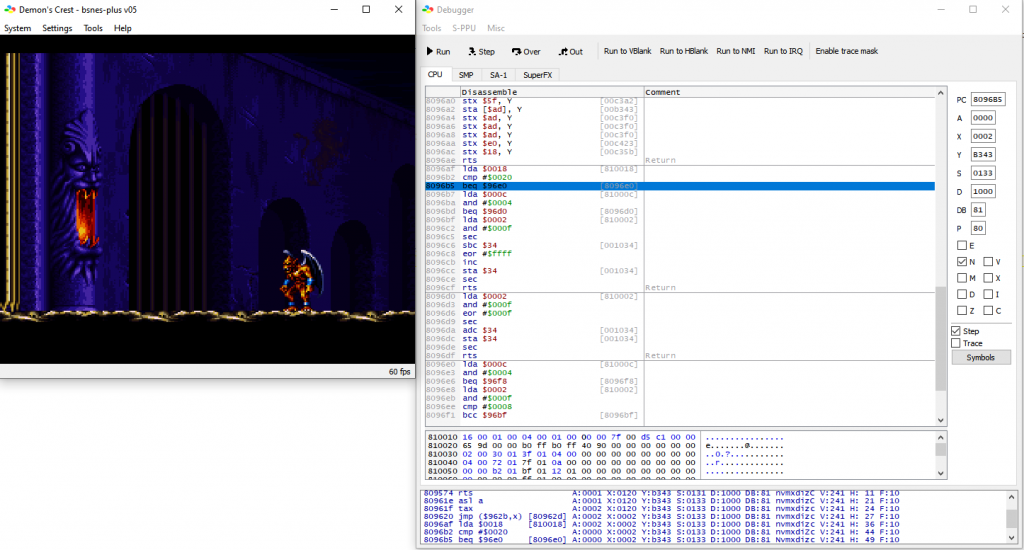
Another example of source-style debugging. The disassembly listing is on the right, with the current instruction highlighted in blue. They go the extra mile and put dividing lines in at observed function boundaries. I don't think that can ever be 100% robust but it's nice regardless.
Or, here's Visual Studio 2019:
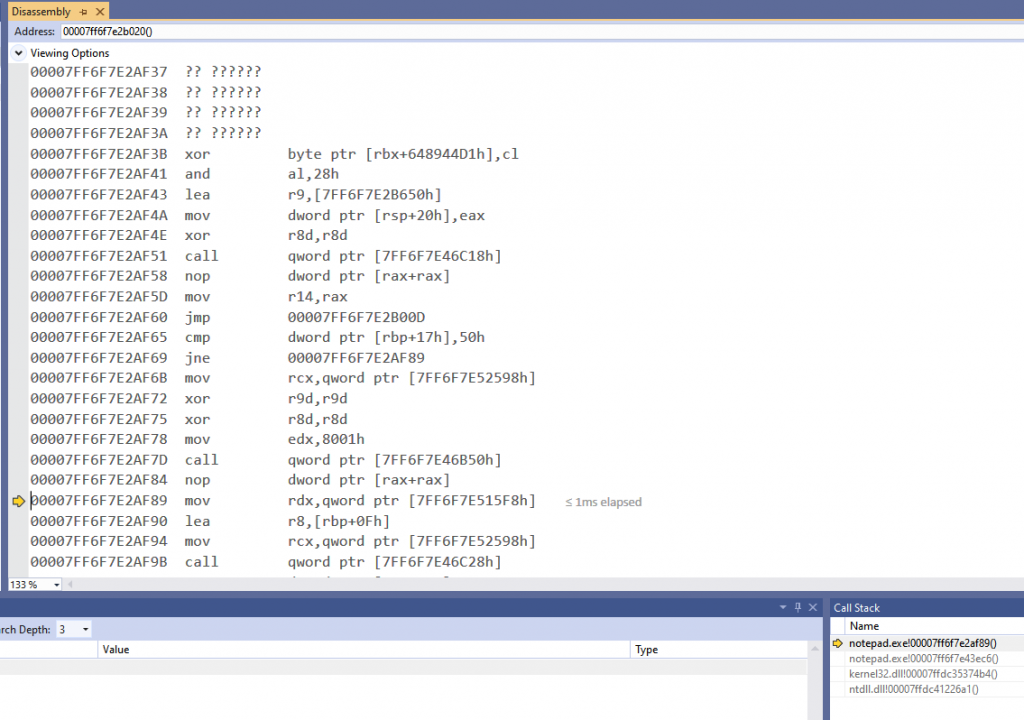
The instructions are listed out. The current instruction is highlighted with a yellow arrow to the left of it. There's some things that couldn't be disassembled so there's a placeholder with question marks.
These are all examples of source-style debugging. It's very popular.
Depending on the implementation, the listing in a source-style debugger can either be
- a local disassembly where all surrounding memory gets interpreted as code, whether it actually is code or not, or
- the result of a tracing, where only executed instructions appear in the listing, creating gaps
The former is a lot more common, as in all the above examples, although I've seen both.
By contrast, a transcript style debugger will look like this:
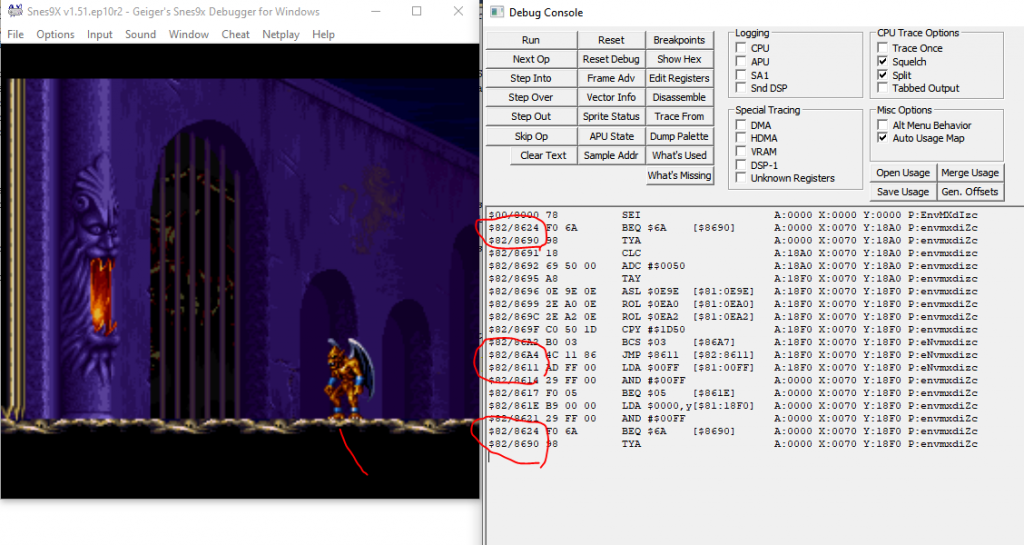
See, there are disjoint instructions, with those pairs circled in red.
Some instructions are listed more than once.
And register state is shown on each line. This platform doesn't have a ton of register space so that's honestly pretty manageable.
The transcript shows all branches with the branch taken, all registers with state at the time, all opcodes with their resolved argument, all loops are unrolled.
The kicker is that implementation of this debugger is dead simple and actually very dumb. It echoes each executed instruction to the output, along with the current register state. That's it.
Yet it is powerful and offers some advantages.
Advantage: history of register values
It's true pretty much all debuggers will show you register values, or variable/memory values at the current instruction. But what about 5 or 10 instructions ago?
You need to either have time-travel debugging, log it, or restart your program.
Some debuggers will cache the "last seen" way something executed (pointer argument, etc), and update it when that instruction is executed again. Great, you can see what was the last way something executed.
But what about the time before that? Or earlier? You can't easily put together a history of what happened unless you log these data points manually yourself.
For reverse-engineering object code with no source code, getting this history is really important in figuring out what happened. You might need to look for trends, look for a pattern, to get a sense of the higher level algorithm. Or you might want transcripts even with code you are familiar with, to get something like a time-travel trace on platforms where actual time-travel isn't available. There's strictly more information in the transcript than in the source-style listing.
"But, it's only outputting registers each line, not all of memory each line". That's true. Each line of the transcript is not a complete state of the machine. I think register state is the right tradeoff to suit most tasks. The exact choice will depend on the platform and the situation. If you're blessed with extensible transcript debugging, that'd probably be the best thing, so you could have like a "watch window" for each line. Generally for SNES, A/X/Y/P is perfectly fine.
Advantage: history of flow control
You can see a clear history of flow control. After all, that's useful. With a couple source-style debuggers, I've seen them do crazy things like try and draw a cute arrow denoting a function was stepped into.
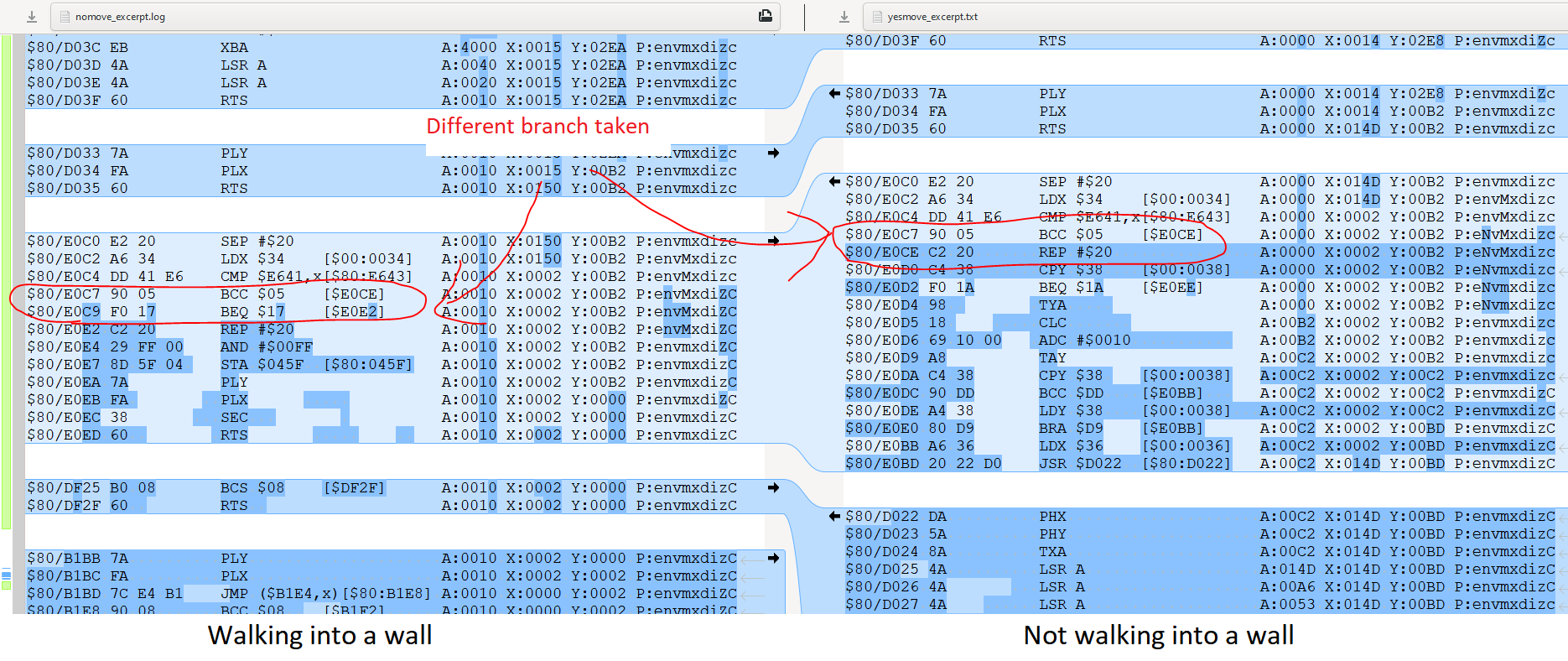
With a transcript, you can see a history of how many times a loop ran, what index of a jump table was used, and which branches had the branch taken. If you save longer transcripts (e.g., with Geiger's SNES debugger's CPU log feature) you can also meaningfully diff transcripts with any text diffing tool of your choice to find divergent control flow like this.
{kind=link}
With source-style debugging, you have no record-keeping of this unless you log it yourself, and you can easily miss what you're looking for.
Advantage: An edge case
This is a bad scenario and not something I've ever seen happen out in the wild.
But you could have it where the same memory is executed twice with the code interpreted in different ways, e.g., 8 bit versus 16 bit native mode.
I don't think a source style debugger could easily make sense of this. A transcript would show what happened clearly.
I made a proof of concept that does this and on testing it doesn't work well at all in a source-style debugger.
Advantage: Don't disassemble stuff that's not code
This is a big one, SNES games will often litter non-code throughout code.
For example of what I mean, this is bsnes broken in NHL '94's graphics decompression
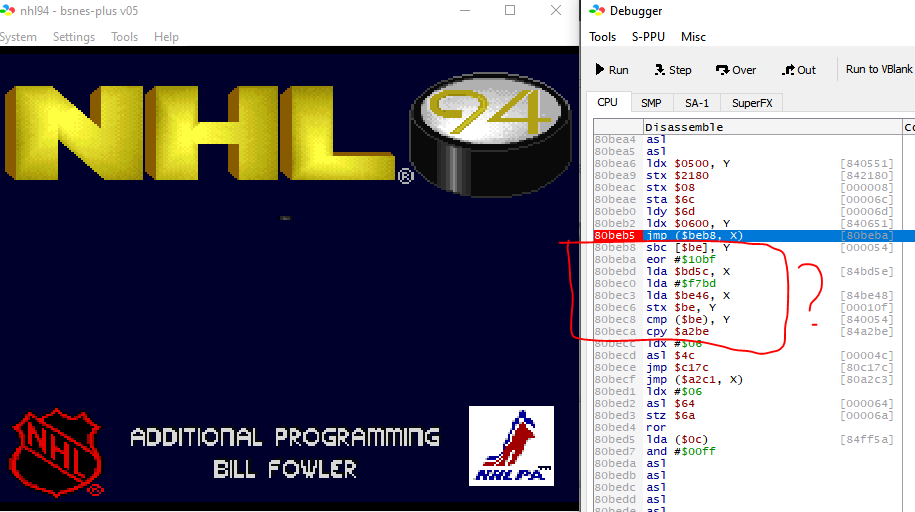
See the part outlined in red. Although there's no obviously illegal instructions, it looks suspicious. Why the CPY with such an arbitrary magic number address? Same with the EOR and the literal, what's up with that? Why the LDAs that immediately get overwritten?
The answer is this isn't code at all. It's data. This source-style debugger will disassemble everything in the neighborhood. That works great only so long as it actually is code. You hope it looks like obvious garbage code, so you can quickly spot it.
In this case, it's actually an array of short pointer offsets baked into the middle of object code. Those are supposed to be offsets, not instructions. If you're really observant you'll see that the preceding JMP $BEB8, X indexes into it and jumps based on an element. It's a hassle to spot this right away, and the debugger isn't doing anything to help you.
Here's another example in a different place
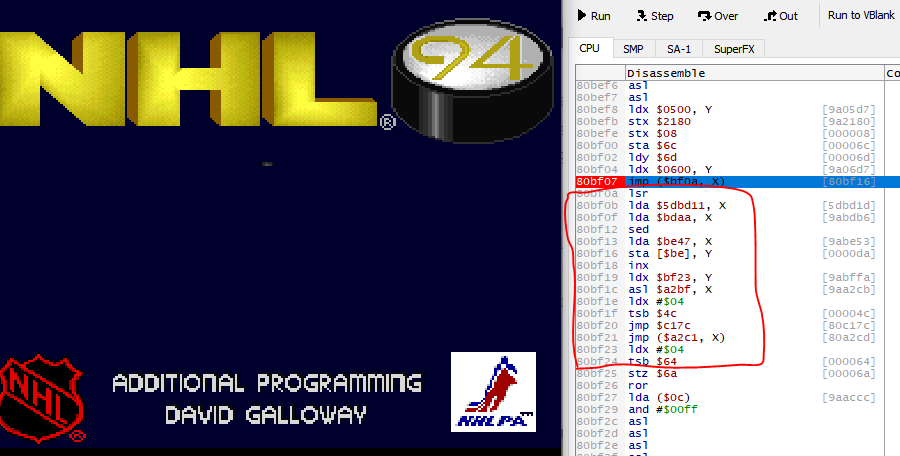
Again red outlined part is not actually code, it's data. This one's sneakier than the above because from a glance it looks less garbage compared to the last one. The big giveaway is SED which is not commonly used.
With transcripts, we don't have this problem. These garbage instructions aren't something you have to discern from non-garbage. Why? Because they don't get executed. They don't even appear.
Why is there data beside the code?
SNES is a different kind of execution environment from what some people are used to.
For the situation above, you might have the reaction "But I work in x86 a lot and I've never seen this before."
Well, x86-64 applications won't have data sprinkled in the code.
Why? Because Intel's architecture does really aggressive instruction prefetching, and the CPU has to know what's code versus what's data for that to work.
You can hear it from Intel themselves:
If (hopefully read-only) data must occur on the same page as code, avoid placing it immediately after an indirect jump. For example, follow an indirect jump with its mostly likely target, and place the data after an unconditional branch.
[...]
Always put code and data on separate pages.
Source: Intel's Optimization Guide
If you write source code that is compiled, the compiler will put object code in the .text segment and constant data in the .rodata segment- it'll do that for you.
Or if you write source code in x86 assembly language, you'd would use a directive like .CODE or .DATA to explicitly define what goes where.
The WDC 65xx-based CPU, on the other hand, is out there living its best life. Memory is just memory, doesn't matter what's where.
Since it doesn't matter at all, it's up to developer preference and convenience. In practice I do notice developers for 65xx platform dump data in the middle of their code like all the time. They'll bake data local in the same bank to take advantage of direct addressing, since if you put all data together it'd have to go in a different bank to fit. Or they're trying to save a MMU page change on certain computers where that matters (e.g., Foenix F256). Or they'll use a self-modified jump instruction instead of a jump table.
So if you work mostly in x86-64 or any other compiler toolchain with the same recommendation, that's one more reason why you probably go through life dealing with source style debuggers. No surprise data tripping you up. It's probably not something you ever think about.
With reverse-engineering on a platform like SNES the value of transcripts is more clear.
Recommendation
Geiger's SNES debugger is a transcript-style debugger, and you should consider it or something similar if you are debugging SNES without source code.
I also think transcript-style debugging is something we as an industry should consider more for debugging object code without source code. The benefit of source-style assembly debugging really only shines when you have symbolic debugging, or corresponding source code.
Using transcripts liberates you where you're not burdened with mapping control flows back to source code, there is only a series of behaviors. You could map them back to code, eventually. It's just not where you start.
Practical justification: I used transcripts to get these done
- Ripping all maps of Lagoon
- Enlarging the hitboxes in Lagoon
- Making an NHL '94 player name, profile and stats editor
- Making an NHL '94 player graphics decompression tool that's 100% accurate to the game's
- Fixed a bug in Lord of the Rings
- Disabling collisions in Lord of the Rings
- Make plants in Harvest Moon be automatically watered
Bonus: Adding transcripts to C256 Foenix IDE debugger
C256 Foenix is a modern WDC 65816-based computer with an emulator.
For personal convenience I added transcript-style debugging to it, looks like this:
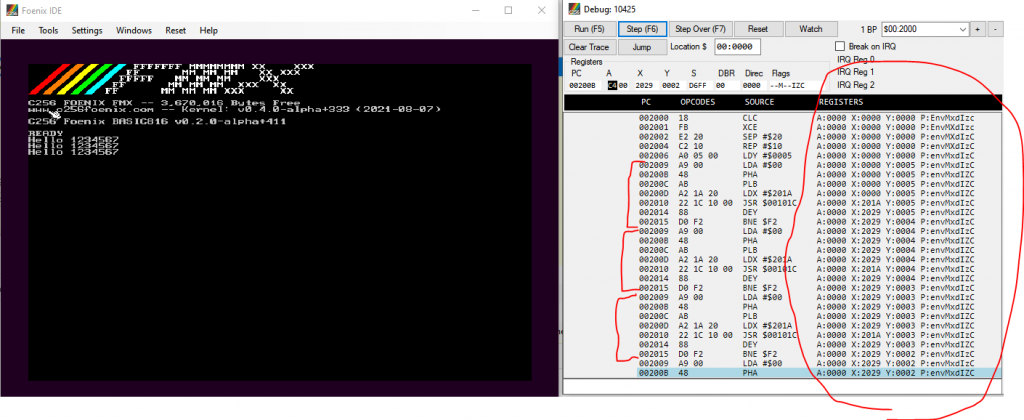
See there's duplicated instructions for a loop, and register output. With source-style, the listing looks like this, which provides a lot less information:

This transcript support is kept side-by-side with the default source-style debugger so that you can switch between them.
Enable it by going to "Settings" and checking the box for "Transcript-style debugger". When the box isn't checked, you get the default source-style debugger. The checkbox setting is remembered like the other settings so you don't need to check it every time.
I've already got some good use out of it. If you want to try it out, it's pushed to this private fork:
https://github.com/clandrew/FoenixIDE/tree/transcript
I did ask the developer of the emulator if he wanted to take a change like this to main. He said no. Not because he wouldn't take changes to the assembly listing format, but because he didn't see the value of transcript debugging.
Say you're writing a Win32 application. You add a toolbar. Simple enough. Toolbar would look better with some things on it.
You want to, say, add a button to it. Like this
Flip through Petzold.
No chapters for toolbar dropdowns.
No obvious samples to use.
We're on our own, then.
Attempt 1: BTNS_DROPDOWN
You follow some of the sample code, and do the most natural thing. Use the toolbar button style 'BTNS_DROPDOWN'. (By the way, BTNS_DROPDOWN is the updated define for TBSTYLE_DROPDOWN. They mean the same thing.)
TBBUTTON tbButtons[] =
{
{ STD_CUT, 0, TBSTATE_ENABLED, BTNS_DROPDOWN, {0}, 0, (INT_PTR)L"Test" },
};
m_hwnd = CreateToolbarEx(
parent,
WS_CHILD | WS_VISIBLE | CCS_ADJUSTABLE | TBSTYLE_TOOLTIPS,
0,
sizeof(tbButtons) / sizeof(TBBUTTON), //nBitmaps
HINST_COMMCTRL,
0, // wBMID
tbButtons, //lpButtons
sizeof(tbButtons) / sizeof(TBBUTTON), // iNumButtons
90, 90, 90, 90,
sizeof(TBBUTTON)); // uStructSize
SetWindowLongPtr(m_hwnd, GWLP_USERDATA, (LONG_PTR)this);
SendMessage(m_hwnd, TB_AUTOSIZE, 0, 0);
ShowWindow(m_hwnd, TRUE);
Compile and run. STD_CUT is your standard built-in Windows scissors 'cut' icon. Result looks like this:
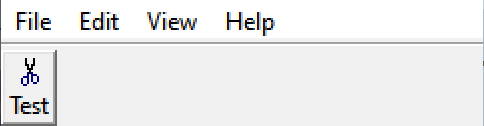
That visually looks fine. But wait. Let's try clicking on it.
It doesn't even show a 'button is pushed' animation. It should at least do that, right?
What gives? It's not disabled.
Attempt 2: TBSTYLE_EX_DRAWDDARROWS
Okay, so maybe our initialization of the dropdown menu was incomplete. Dropdown menus usually have an arrow at the right. Perhaps we need to add the "arrow at the right" extended style? Let's try adding the code
SendMessage(m_hwnd, TB_SETEXTENDEDSTYLE, 0, TBSTYLE_EX_DRAWDDARROWS);So that now, it looks like
TBBUTTON tbButtons[] =
{
{ STD_CUT, 0, TBSTATE_ENABLED, BTNS_DROPDOWN, {0}, 0, (INT_PTR)L"Test" },
};
m_hwnd = CreateToolbarEx(
parent,
WS_CHILD | WS_VISIBLE | CCS_ADJUSTABLE | TBSTYLE_TOOLTIPS,
0,
sizeof(tbButtons) / sizeof(TBBUTTON), //nBitmaps
HINST_COMMCTRL,
0, // wBMID
tbButtons, //lpButtons
sizeof(tbButtons) / sizeof(TBBUTTON), // iNumButtons
90, 90, 90, 90,
sizeof(TBBUTTON)); // uStructSize
SendMessage(m_hwnd, TB_SETEXTENDEDSTYLE, 0, TBSTYLE_EX_DRAWDDARROWS);
SetWindowLongPtr(m_hwnd, GWLP_USERDATA, (LONG_PTR)this);
SendMessage(m_hwnd, TB_AUTOSIZE, 0, 0);
ShowWindow(m_hwnd, TRUE);
Let's compile and run it and see what it looks like now.
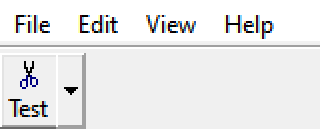
This looks better. There's an arrow on the right. That should mean something good. Let's try clicking on it.
Clicking on the button itself works.
Clicking on the arrow doesn't 🙁
Attempt 3: BTNS_WHOLEDROPDOWN
Maybe the ticket is WHOLEDROPDOWN. Looking it up in the header, BTNS_WHOLEDROPDOWN purports to

That sounds like it could make the whole button appear responsive, so why not let's try it.
Result looks like this:
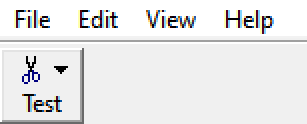
Okay. What if we try to click on it?
Nothing happens 🙁
What to do?
The Answer
The answer: toolbar dropdown menus, by default, don't have any animation for clicking on them. They're not like normal buttons. That's right, the button is still working, there's just no visual feedback unless you explicitly attach some yourself.
To make the toolbar dropdown button do something, you have to just trust that it is set up ok, and attach some behavior to the dropdown notification.
Fortunately you don't have to re-invent the wheel to do that. Here's an easy way to attach a simple pop-up menu to the dropdown.
First, you need to have your WndProc pay attention to WM_NOTIFY. The handler can be something like
case WM_NOTIFY:
{
LPNMTOOLBAR lpnmtb = (LPNMTOOLBAR)lParam;
if (lpnmtb->hdr.code == TBN_DROPDOWN)
{
// Get the coordinates of the button.
RECT rc;
SendMessage(lpnmtb->hdr.hwndFrom, TB_GETRECT, (WPARAM)lpnmtb->iItem, (LPARAM)&rc);
// Convert to screen coordinates.
MapWindowPoints(lpnmtb->hdr.hwndFrom, HWND_DESKTOP, (LPPOINT)&rc, 2);
HMENU hMenuLoaded = LoadMenu(g_hInst, MAKEINTRESOURCE(IDR_MENU1));
// Get the submenu for the first menu item.
HMENU hPopupMenu = GetSubMenu(hMenuLoaded, 0);
TPMPARAMS tpm;
tpm.cbSize = sizeof(TPMPARAMS);
tpm.rcExclude = rc;
TrackPopupMenuEx(hPopupMenu, TPM_LEFTALIGN | TPM_LEFTBUTTON | TPM_VERTICAL, rc.left, rc.bottom, hWnd, &tpm);
DestroyMenu(hMenuLoaded);
}
break;
}As for the menu IDR_MENU1, you can point it to a menu you have defined. Or, if you want a placeholder thing, put something like this in your .rc file:
IDR_MENU1 MENU
BEGIN
POPUP "TEST"
BEGIN
MENUITEM "Option 1", ID_TEST_OPTION1
MENUITEM "Option 2", ID_TEST_OPTION2
END
ENDThat goes along with these defines in the Resources.h coupled to the .rc file:
#define IDR_MENU1 132
#define ID_TEST_OPTION1 32777
#define ID_TEST_OPTION2 32778Build, and you get this:
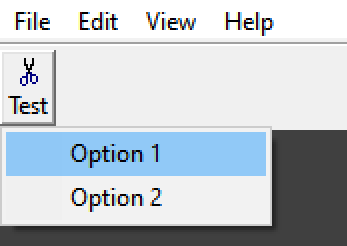
In animated form:
The dropdown works. Success!
It so happens if you re-try Attempt 2, TBSTYLE_EX_DRAWDDARROWS with a pop up menu, then it'll provide visual arrow-is-pressed feedback where it didn't before. See:
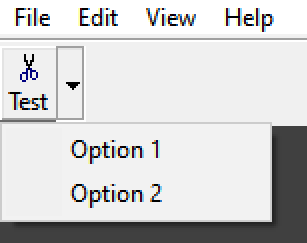
This is because BTNS_DROPDOWN, TBSTYLE_EX_DRAWDDARROWS, and BTNS_WHOLEDROPDOWN follow a common principle: anything that appeared unresponsive with no pop up menu attached is responsive once a menu is attached.
This system was not super well explained elsewhere, so maybe this will help you.
I made a Visual Studio extension for 65C816 syntax highlighting. Suitable for SNES or C256 Foenix projects. Looks like this:

The source+binary are on GitHub, here: https://github.com/clandrew/vscolorize65c816
I had some past experience working on a big existing system in a Visual Studio extension in a job I had a little while ago. This was my first time writing an extension for a recent version from scratch. The experience was different.
I accomplished what I set out to do and it's working well, but the path of getting there was cumbersome.
Here is a list of the problems I ran into.
Problem: No extension template.
Root cause: Template requires an optional add-on.
How debugged: search engine.
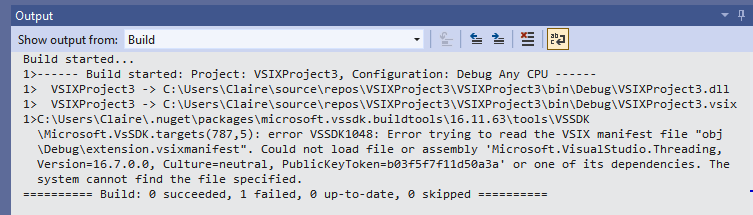
Problem: Official template has build error right out of the gate:
error VSSDK1048: Error trying to read the VSIX manifest file "obj\Debug\extension.vsixmanifest". Could not load file or assembly 'Microsoft.VisualStudio.Threading, Version=16.7.0.0, Culture=neutral, PublicKeyToken=b03f5f7f11d50a3a' or one of its dependencies. The system cannot find the file specified.
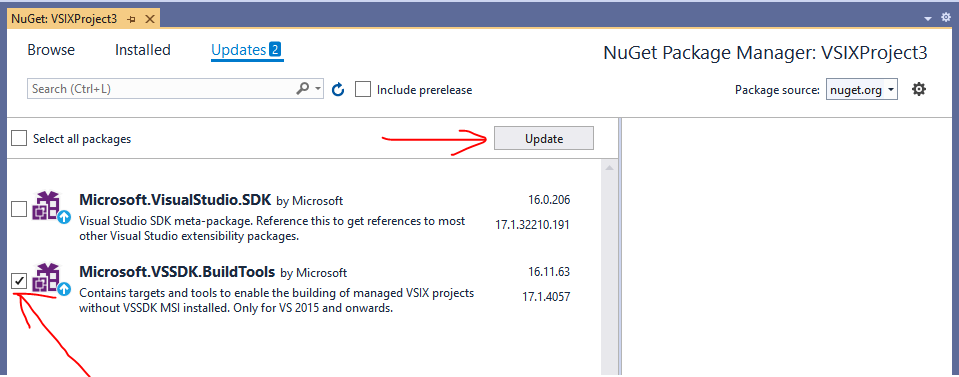
Root cause: The template has a missing dependency. To fix, you have to update the NuGet package "Microsoft.VSSDK.BuildTools".
How debugged: Shotgun debugging
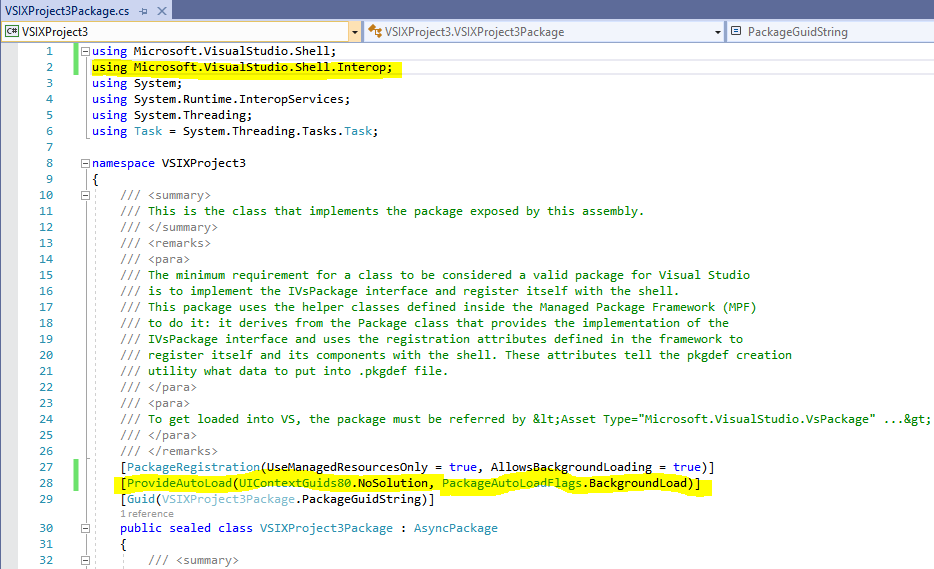
Problem: Template does not behave correctly out of the gate. When launched with debugger, it is never loaded
Root cause: The template is missing an attribute
How debugged: Search engine
You don't create a syntax highlighter object out of the blue. You define a 'Package' object to set it up. I defined one in code.
Problem: Package object is never instantiated.
Root cause: You have to define, at a minimum, two attributes to make it get loaded: [PackageRegistration] and [ProvideAutoLoad].
How debugged: Looking at other extensions as examples + shotgun debugging
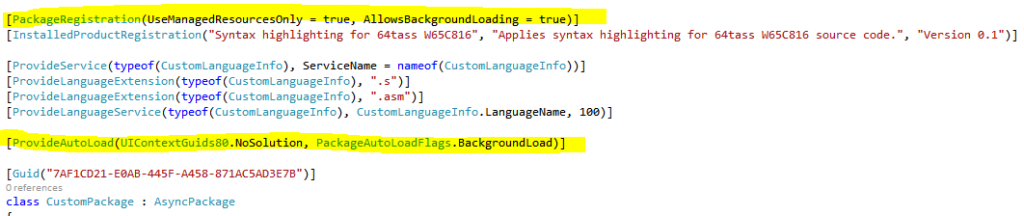
Problem: The package is instantiated, but doesn't correctly associate with the intended files. Error message when opening files that have ProvideLanguageExtension. "An error occured in 'file' when attempting to open 'file.s'. There is no editor available for 'file.s'. Make sure the application for the file type (.s) is installed."
Root cause: Something is stale. Reload the file! Even if you restart the whole IDE, it's not enough! It stays stale unless you specifically reload the file
How debugged: Shotgun debugging
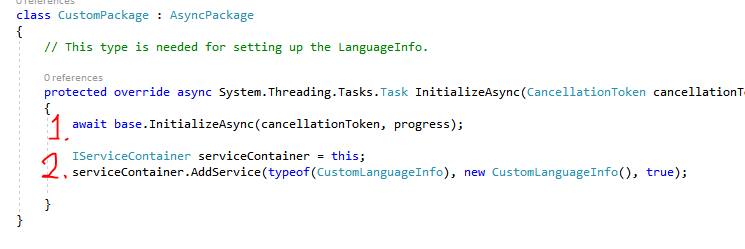
Problem: The package adds a LanguageInfo service, but the LanguageInfo is never instantiated.
Root cause: You have to call AddService after InitializeAsync, not before
How debugged: Shotgun debugging + code examples
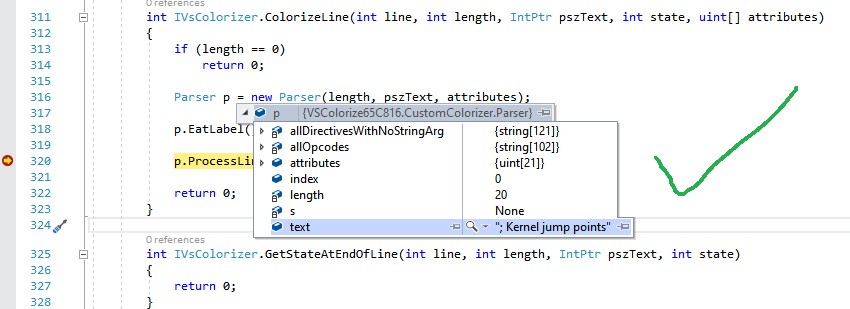
Problem: The syntax is not highlighted as intended
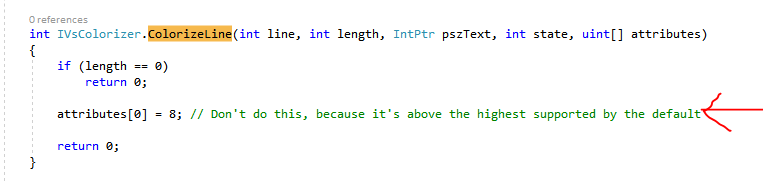
Root cause: Need to have IVsColorizer::ColorizeLine return the intended values
How debugged: Actual debugging
Problem: The choice of which attribute value maps to which color seems arbitrary
Root cause: There is a system of default colors. You can know that default through experimentation, or over-ride it in a specific way
How debugged: Experimentation
Takeaway- I accomplished what I was trying to do, but there was a lot of shotgun debugging and 'just trying things'. The extension framework has you hook into a complicated system which is also closed-off and opaque, so there is no way to directly debug it.
It may as well be running on a different computer.
By "system", I'm referring to
- The mechanism that instantiates your custom package and calls InitializeAsync on it
- The thing that looks at your custom package and loads it based on PackageRegistration
- The thing that sets up associations using package attributes like ProvideLanguageExtension.
- The thing that executes methods of objects set up with IServiceContainer::AddService
Look at my extension or other people's samples. You're supposed to define a **** ton of attributes on the Package class.
Here's an example from an open source project on GitHub:
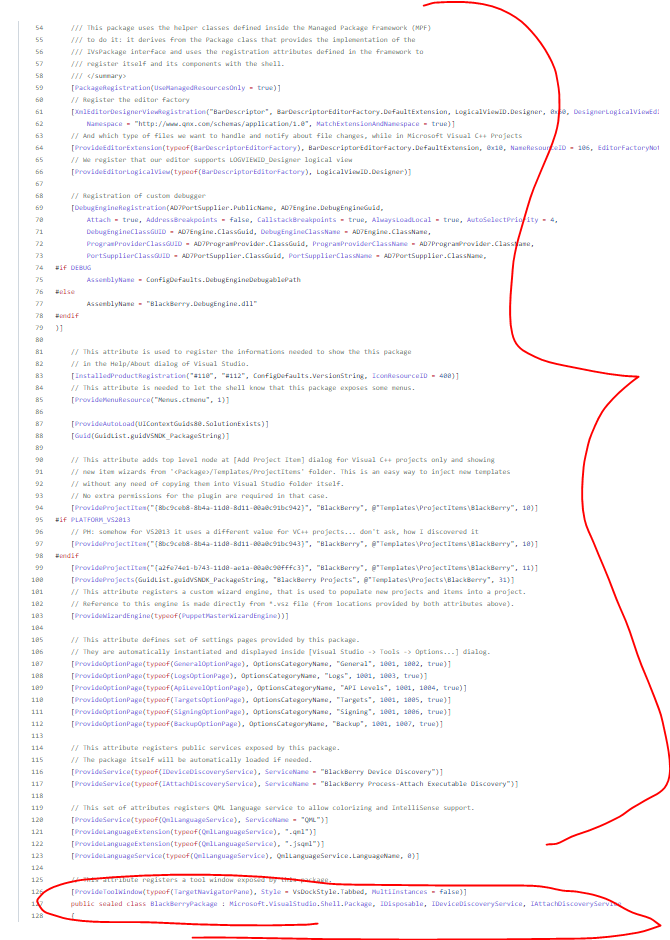
It's to the point where the attributes are really a language in and of themselves. Guess what, they feed into some complicated loader that executes before your code is ever executed. If there's a mistake in the attributes? Get your psychic powers ready. Because there's no insight into this closed system or way see what it's doing. It doesn't even have the decency to put its state to debug console.
The time I spent actually debugging problems was in the minority. Most problems, the only way to fix them was by trying things. It's really bad. They could not be debugged in the debugger because they occur in a complicated system you don't have access to. This system and its higher-level concepts were not documented well enough to automatically know what to type. "Is ProvideLanguageService not supposed to have languageResourceID 100? Is that the reason it's failing, or something else?"
I'm not even angry about the 17KB of code and god knows how much memory it takes to make text a different color according to a simple scheme. What's really bad is this this closed off system that everyone is supposed to just be okay with, since I see it as part of a trend. UI layouts from markup are like this. App store launching is like this. Software junk food "press F5"-style emulators and VMs are like this. As we get more and more complicated software systems, there isn't enough follow-through to make them fully open and debuggable. So if they 'just work the first time' fantastic. But we all live in reality. Things will go wrong, and when they do, it's clear the system is grand and complicated and undocumented and undiagnosable.
As a random example, can you imagine if Direct3D 12 had no debug layer, and all it told you was E_INVALIDARG? Why would we accept this more broadly?
This is why I keep writing GUI applications as executables with Win32 or Windows Forms say. The form designer has the decency to give you a call stack. Actionable stack or some error string should be the bare minimum.
Shifting topics, here are things I learned about Visual Studio custom colorizers:
- The 'state' values passed to/from your callbacks have whatever meaning you want them to. The meaning of states is all user-defined. It's opaque to Visual Studio.
- An IVsLanguageInfo is reponsible for providing two things: a colorizer, and a code window manager. But you don't need to have both. You can just provide one if you want. For example you can provide a colorizer, but return E_NOTIMPL to IVsLanguageInfo::GetCodeWindowManager.
- In IVsColorizer::ColorizeLine, character at index N in the 'pszText' corresponds to element N of 'attributes' parameter.
- To add colors to text, you set values in the 'attributes' parameter of IVsColorizer::ColorizeLine. Like this:
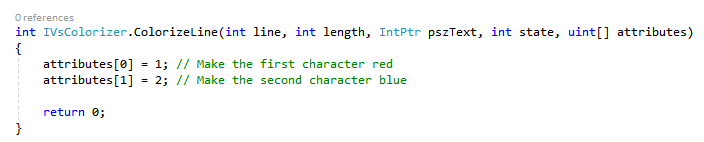
Why does 1 mean red? Because it's based on whatever you set in your IVsProvideColorableItems callback object.

Yes, it's 1-indexed.
If you don't have an IVsProvideColorableItems set up, you'll get some defaults with blue, green, red, and black (default) text numbered in some way. You can experiment what means what. Using a value of greater than 6 will crash the extension, so that's fun. In my case, the default was almost good enough, but I wanted gray for directives like C++ has, for e.g., #include and #pragma. So I did end up implementing IVsProvideColorableItems.
All told, if you use the syntax highlighter with custom build tools, it looks like this:

so the experience is pretty smooth.
Direct download to the release is here https://github.com/clandrew/vscolorize65c816/releases/tag/v1.0.
Here is some C++:
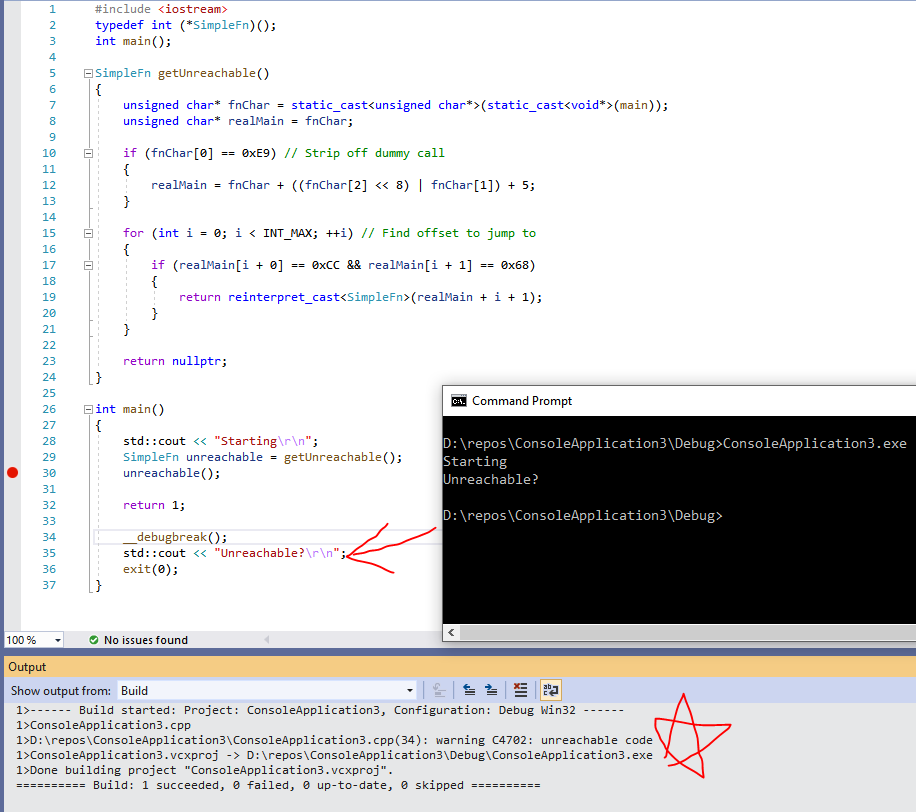
compiled to x86.
Obvious disclaimer this is brittle, very platform and compiler dependent, will break if you look at it the wrong way.
How it works: this part
if (fnChar[0] == 0xE9) // Strip off dummy call
{
realMain = fnChar + ((fnChar[2] << 8) | fnChar[1]) + 5;
}is because some compiler settings can mean your functions are called from jump thunks. For example, if you take the address of function "main", stored as fnChar, it gives you
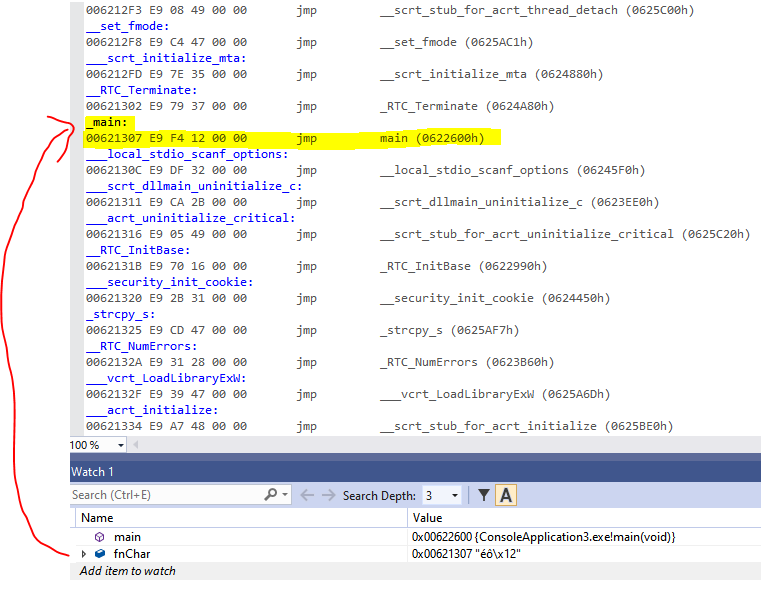
Rather than the function body you'd expect, it's an entry in a sea of jumps. These are incremental linking jump thunks. While we could deal with this by disabling incremental linking, it's not too hard to robustify against. To look up what's the "real" address of main, the code looks at the offset of the jump-relative, adds it on plus 5 which is the length of the jmp operation.
After that is this part:
for (int i = 0; i < INT_MAX; ++i) // Find offset to jump to
{
if (realMain[i + 0] == 0xCC && realMain[i + 1] == 0x68)
{
return reinterpret_cast<SimpleFn>(realMain + i + 1);
}
}This seeks through main for some delimiter. The delimiter, in this case, is

Wherever it finds the int 3 delimiter, that's the code we want to call. Could key off of only 0xCC but that's a very common term, it also happens to be used for setting up an argument to __CheckForDebuggerJustMyCode, so use the first byte of the subsequent push to dis-ambiguate.
And finally, the
exit(0);is a cheesy trick to compensate for the fact that we didn't set up the stack frame properly. We'd run into this problem when jumping into the middle of almost any function (by messing with the function pointer). As far as the compiler's concerned, you're supposed to jump to the beginning of functions. By jumping into the middle, we skip a bunch of initialization, like the allocation of stack-allocated variables in function scope. And switching to global variables doesn't help for debug. When compiling for debug, the generated code allocates stack space automatically for you even if you have no local variables.
When main exits, it'll compare the stack pointer, and make sure it reflects base pointer + stack allocation to make sure nothing corrupted the value of the stack pointer somehow. This validation would catch a legitimate issue in this case. Bailing out with exit avoids the whole thing.
In all, this is a case where the compiler says you have code that's not reachable but it actually is.
The principle of this being possible is obvious to some people, but not all. I've had people say to me that "good compilers can always 100% statically know if code is reachable or not". It's not true, for C++ to x86 anyway. I tell them, "No, code is just code. At the end of the day, if code exists in a binary, you can execute it. Compilers can't exhaustively evaluate what generated code will do. They can't solve the halting problem" They don't understand what I mean and there's a gap in understanding so I hope a proof-by-example would explain, even if it's a super contrived and impractical one.
"But what if I enable optimizations?" If you enable optimizations, the code labeled "unreachable" will be actually missing from the binary. Yes that means the compiler is wrong. To work around I'd suggest adding some dummy control flow to tell the compiler the code is reachable.
This was tested using MSVC. GNU C has some additional semantics around gotos and labels (e.g., && operator) where you can encounter this more readily.
If you want to try the above code, here:
Answer: mostly, yes. Explanation below.
Part 1: Yes or No
Remember GDI? Say you're using GDI and Win32, and you want to draw some graphics to a window. What to do. You read the documentation and see what looks like the most obvious thing: "SetPixel". Sounds good. Takes an x and y and a color. What more could you want? Super easy to use.
But then, you see a bunch of cautionary notes. "It's slow." "It's inefficient." "Don't do it."
Don't do it?
Well. All these cautionary notes you see are from days of yore:
- Computers are faster now. Both CPU and GPU. Take an early CS algorithms class, experiment with solutions. You’ll see sometimes the biggest optimization you can do is to get a faster computer.
- An earlier Windows graphics driver model. Say, XPDM not WDDM. WDDM means all hardware-accelerated graphics communicate through a “Direct3D-centric driver model”, and yes that includes GDI. Changes in driver model can impose changes in performance characteristics.
- Different Windows presentation model. That's something this API is set up to negotiate with, so it could affect performance too. Nowadays you're probably using DWM. DWM was introduced with Windows Vista.
The date stamps give you skepticism. Is that old advice still true?
As a personal aside, I've definitely seen performance advice from people on dev forums that is super outdated and people get mis-led into following it anyway. For example for writing C++ code, to "manually turn your giant switch case into a jump table". I see jump tables in my generated code after compilation... The advice was outdated because of how much compilers have improved. I've noticed a tendency to trust performance advice "just in case", without testing to see if it matters.
Let us run some tests to see if SetPixel is still slow.
I wrote a benchmark program to compare
- SetPixel, plotting each pixel of a window sequentially one by one, against
- SetDIBits, where all pixels of a window are set from memory at once.
In each case the target is a top-level window, comparing like sizes. Each mode effectively clears the window. The window is cleared to a different color each time, so you have some confidence it’s actually working.
Timing uses good old QPC. For the sizes of timespans involved, it was not necessary to get something more accurate. The timed interval includes all the GDI commands needed to see the clear on the target, so for SetDIBits that includes one extra BitBlt from a memory bitmap to the target to keep things fair.
The source code of this benchmark is here.
Here are the results
| Width | Height | Pixel Count | SetPixel | SetDIBits |
| 1000 | 1000 | 1000000 | 4.96194 | 0.0048658 |
| 950 | 950 | 902500 | 4.7488 | 0.0042761 |
| 900 | 900 | 810000 | 4.22436 | 0.0038637 |
| 850 | 850 | 722500 | 3.71547 | 0.0034435 |
| 800 | 800 | 640000 | 3.34327 | 0.0030824 |
| 750 | 750 | 562500 | 2.92991 | 0.0026711 |
| 700 | 700 | 490000 | 2.56865 | 0.0023415 |
| 650 | 650 | 422500 | 2.21742 | 0.0022196 |
| 600 | 600 | 360000 | 1.83416 | 0.0017374 |
| 550 | 550 | 302500 | 1.57133 | 0.0015125 |
| 500 | 500 | 250000 | 1.29894 | 0.001311 |
| 450 | 450 | 202500 | 1.05838 | 0.0010062 |
| 400 | 400 | 160000 | 0.826351 | 0.0009907 |
| 350 | 350 | 122500 | 0.641522 | 0.0006527 |
| 300 | 300 | 90000 | 0.467687 | 0.0004657 |
| 250 | 250 | 62500 | 0.327808 | 0.0003364 |
| 200 | 200 | 40000 | 0.21523 | 0.0002422 |
| 150 | 150 | 22500 | 0.118702 | 0.0001515 |
| 100 | 100 | 10000 | 0.0542065 | 9.37E-05 |
| 75 | 75 | 5625 | 0.0315026 | 0.000122 |
| 50 | 50 | 2500 | 0.0143235 | 6.17E-05 |
Viewed as a graph:
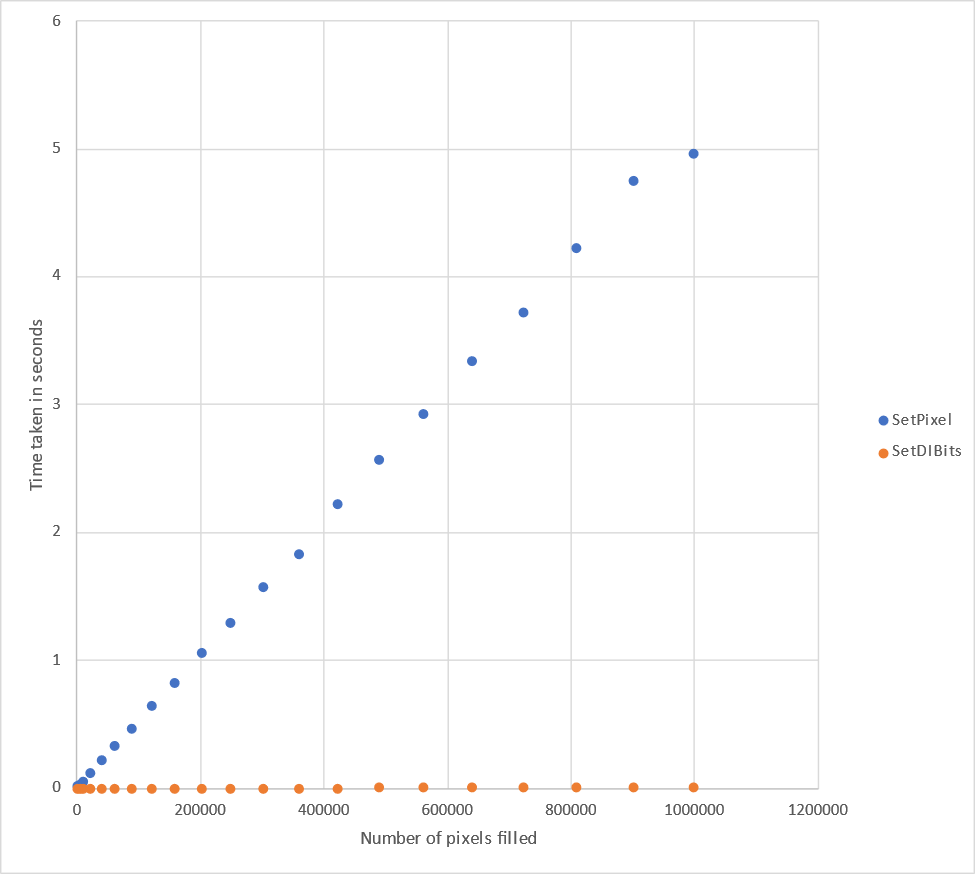
Conclusion: yeah, SetDIBits is still way faster than SetPixel in general, in all cases.
For small numbers of pixels, the difference doesn't matter as much. For setting lots of pixels, the difference is a lot.
I tested this on an Intel Core i7-10700K, with {NVIDIA GeForce 1070 and WARP} with all similar results.
So the old advice is still true. Don't use SetPixel, especially if you’re setting a lot of pixels. Use something else like SetDIBits instead.
Part 2: Why
My benchmark told me that it’s still slow, but the next question I had was ‘why’. I took a closer look and did some more thinking about why it could be.
It's not one reason. There's multiple reasons.
1. There's no DDI for SetPixel.
You can take a look through the public documentation for display devices interfaces, and see what’s there. Or, take a stab at it and use the Windows Driver Kit and the provided documentation to write a display driver yourself. You’ll see what’s there. You’ll see various things. You’ll see various blit-related functions in winddi.h. For example, DrvBitBlt:
BOOL DrvBitBlt(
[in, out] SURFOBJ *psoTrg,
[in, optional] SURFOBJ *psoSrc,
[in, optional] SURFOBJ *psoMask,
[in] CLIPOBJ *pco,
[in, optional] XLATEOBJ *pxlo,
[in] RECTL *prclTrg,
[in, optional] POINTL *pptlSrc,
[in, optional] POINTL *pptlMask,
[in, optional] BRUSHOBJ *pbo,
[in, optional] POINTL *pptlBrush,
[in] ROP4 rop4
);That said, you may also notice what’s not there. In particular, there’s no DDI for SetPixel. Nothing simple like that, which takes an x, y, and color. It’s important to relate this to the diagrams on the “Graphics APIs in Windows” article, which shows that GDI talks to the driver for both XPDM and WDDM. It shows that every time you call SetPixel, then what the driver sees is actually far richer than that. It would get told about a brush, a mask, a clip. It’s easy to imagine a cost to formulating all of those, since they you don’t specify them at the API level and the API is structured so they can be arbitrary.
2. Cost of talking to the presentation model
There’s a maybe-interesting experiment you can do. Write a Win32 application with your usual WM_PAINT handler. Run the application. Hide the window behind other windows, then reveal it once again. Does your paint handler get called? To reveal the newly-revealed area? No, normally it doesn’t.
So what that must logically mean is that Windows kept some kind of buffer, or copy of your window contents somewhere. Seems like a good idea if you think about it. Would you really want moving windows around to be executing everyone’s paint handlers all the time, including yours? Probably not. It’s the good old perf-memory tradeoff in favor of perf, and it seems worth it.
Given that you’re drawing to an intermediate buffer, then there’s still an extra step needed in copying this intermediate buffer to the final target. Which parts should be copied, and when? It seems wasteful to be copying everything all the time. To know what needs to get re-copied, logically there has to be some notion of an “update” region, or a “dirty” region.
If you’re an application, you might even want to aggressively optimize and only paint the update region. Can you do that? At least at one point, yes you could. The update region gets communicated to the application through WM_PAINT- see the article “Redrawing in the Update Region”. There’s a code example of clipping accordingly. Now, when I tried things out in my application I noticed that PAINTSTRUCT::rcPaint is always the full window, even in response to a small region invalidated with InvalidateRect, but the idea is at least formalized in the API there.
Still, there’s a cost to dealing with update regions. If you change one pixel, that one-pixel area is part of the update region. Change the pixel next to it, the region needs to be updated again. And so on. Could we have gotten away with having a bigger, coarser update region? Maybe. You just never know that at the time.
If you had some way of pre-declaring which regions of the window you’re going to change, (e.g., through a different API like BitBlt), then you wouldn’t have this problem.
3. Advancements in the presentation model help, but not enough
In Windows, there is DWM- the Desktop Window Manager. This went out with Windows Vista and brought about all kinds of performance improvements and opportunity for visual enhancements.
Like the documentation says, DWM makes it possible to remove level of indirection (copying) when drawing contents of Windows.
But it doesn’t negate the fact that there still is tracking of update regions, and all the costs associated with that.
4. Advancements in driver model help, but not enough
DWM and Direct3D, as components that talk to the driver through the 3D stack, have a notion of “frames” and a particular time at which work is “flushed” to the GPU device.
By contrast, GDI doesn’t have the concept of “frames” or flushing anything. Closest thing would be the release of the GDI device context, but that’s not strictly treated as a sign to flush. You can see it yourself in how your Win32 GDI applications are structured. You draw in response to WM_PAINT. Yes there is EndPaint, but EndPaint doesn’t flush your stuff. Try it if you want- comment out EndPaint. I tried it just to check and everything still works without it.
Since there isn’t a strict notion of “flushing to the device”, SetPixel pixels have to be dispatched basically immediately rather than batched up.
5. 3D acceleration helps, but not enough
Nowadays, GDI blits are indeed 3D accelerated.
- They were,
- then they weren’t for Vista,
- then they were again.
I noticed this firsthand, too. Very lazy way to check- in the “Performance” tab in Task manager when I was testing my application, I saw little blips in the 3D queue. These coincided with activity in the SetPixel micro-benchmark.
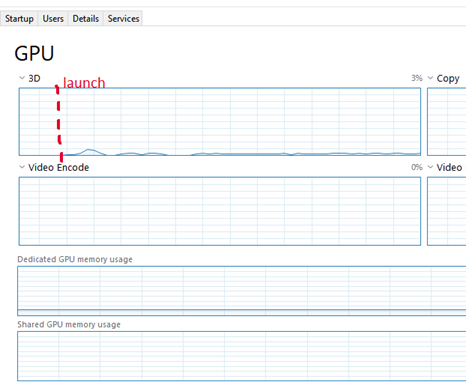
Again, very lazy check. Good to know we are still accelerating these 2D blits, even as the graphics stack has advanced to a point of making 3D graphics a first-class citizen. Hardware acceleration is great for a lot of things, like copying large amounts of memory around at once, applying compression or decompression, or manipulating data in other ways that lend itself to data-parallelism.
Unfortunately, literally none of that helps this scenario. Parallelism? How? At a given time, the driver doesn’t know if you’re done plotting or what you will plot next or where. And it can’t buffer up the operations and execute them together, because it, like Windows, doesn’t know when you’re done. Maybe, it could use some heuristic.
But that brings this to the punchline: even if the driver had psychic powers, it could see into the future and know exactly what the application is going to do and did an absolutely perfect job of coalescing neighboring blits together, it doesn’t negate any of the above costs, especially 1. and 2.
Conclusion
Even in the current year, don’t use SetPixel for more than a handful of pixels. There’s reasons to believe the sources of the bottlenecks to have changed over 30 years, yet even still the result is the same. It’s slow and the old advice is still true.
Epilogue: some fantasy world
This post was about how things are. But, what could be? What would it take for SetPixel not to be slow? The most tempting way to think about this is to flatten or punch holes through the software stack. That works, even if it feels like a cop-out.
J. R. R. Tolkien's Lord of the Rings for Super Nintendo shipped with a bug as you get toward the later parts of the game.
Short version: use these Pro Action Replay codes to un-glitch the late-game passwords.
81CBF10C
81A3900C
81A35C0CLonger explanation below.
If you're in Moria past the entrance and the first part and request a password, the game will give you one. However, if you write down and try to use that same password later, the game won't accept it.
This is especially troublesome because
a) it's in the most tedious part of the game, a part you wouldn't ever want to re-do, and
b) even if you back-track to the Moria entrance, it won't go back to giving you valid passwords. The game's password system is basically cursed.
I investigated to understand this more. First, the password validation converts this character into a number.
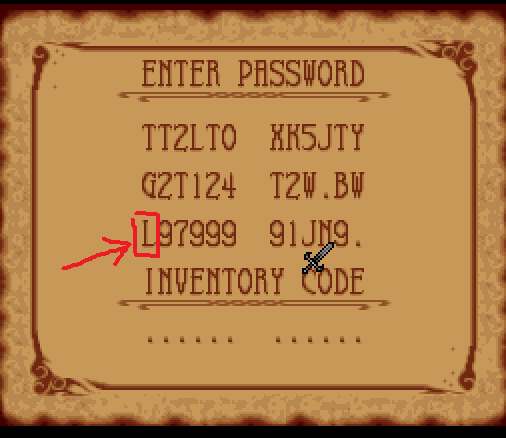
The exact way it does this is described in an earlier post. So for here, L is 9, M would be 10, and so on.
Starting from there, I found out more by
- typing a numerical garbage password like "023741" into the first six characters
- taking memory dump of RAM
- running a relative searcher on the memory dump, looking for a pattern like the one above
- found one result. This was lucky in a bunch of ways. It was lucky how the number was indeed stored contiguously in RAM, not immediately over-written, the password characters' values are sequential (e.g., the value of password character '1' numerically comes right before '2') and that I had picked a unique enough number
- Used that to get the RAM address of the character boxed in red above
- Set a break-on-read of that RAM address in the debugger
- Breakpoint hit when you press the button for password confirm. This also, was a bit lucky. The game only read the password back for initial graphics or when you hit 'confirm'. No reading it back continuously, no noisy breakpoints.
- Stepped through in debugger to see what it did with the password character. When it copied the password character, set break-on-read of that too. This led to un-tangling the password characters from what I called the AreaNumbers below. I saved the code and marked it up with comments and labels.
Password validation calls this function
// Function: ReadPasswordLocationCode()
// Precondition: location code is stored at $81:039C
// Postcondition: result stored in 801CCB, 801CCD, 801CC9.
// The result is what I'm calling an "AreaNumber"
// plus positional information about
// where in the world to load the player.
//
// Early-game AreaNumbers are high-numbered.
// Late-game ones are low.
// Examples:
// Crossroads is 0x12A.
// Rivendell is 0x138.
// Moria Entrance is 0xEF.
// Moria 1 is 0x51.
// Moria 2 is 0x0C.
$81/CBEA B9 84 03 LDA $0384,y[$81:039C] ; Load location code. E.g., the password
; character 'M', which is 0xA
$81/CBED 29 1F 00 AND #$001F ; Ignore upper bits
$81/CBF0 C9 0A 00 CMP #$000A
$81/CBF3 90 02 BCC $02 [$CBF7] ; If the password character is equal or greater than
;'M' (0xA), fall through
; to LocationCodeTooHigh.
; Otherwise, goto LocationCodeOk.
LocationCodeTooHigh:
$81/CBF5 38 SEC
$81/CBF6 6B RTL ; Bail
LocationCodeOk:
$81/CBF7 85 90 STA $90 [$00:0090]
$81/CBF9 A5 90 LDA $90 [$00:0090]
$81/CBFB 0A ASL A
$81/CBFC AA TAX
// Write the output
$81/CBFD BF 18 CC 81 LDA $81CC18,x[$81:CC2A]
$81/CC01 8F CB 1C 80 STA $801CCB[$80:1CCB]
$81/CC05 BF 30 CC 81 LDA $81CC30,x[$81:CC42]
$81/CC09 8F CD 1C 80 STA $801CCD[$80:1CCD]
$81/CC0D BF 48 CC 81 LDA $81CC48,x[$81:CC5A]
$81/CC11 8F C9 1C 80 STA $801CC9[$80:1CC9]
$81/CC15 C8 INY
$81/CC16 18 CLC
$81/CC17 6B RTL It's pretty easy to see the problem. It validates your location code is too high if you specify 'M' or 'N', but those are codes the game gives you. It was clearly a mistake. Changing the line
$81/CBF0 C9 0A 00 CMP #$000Ato
$81/CBF0 C9 0C 00 CMP #$000Cwill fix it, allowing through AreaNumbers up to N (since a password character N = 11 = 0xB), the maximum the game will give you.
This unblocks the password validation code. But, if you were to patch the above change and try it, you'd see the screen fade but hang there forever spinning in a long loop and hard locked not loading the level. So we're not out of the woods yet.
Terminology
Crashed, halted- the game's computer stopped executing instructions
Hard lock- the game's computer is executing instructions, but it appears unresponsive to inputs e.g., the screen is black
Soft lock- the game displays graphics and appears responsive but can not be won
The hang happens because we get past the password-validation and into level-loading yet there's parts of the level loading code that block out AreaNumbers belonging to Moria.
We get here
// Function: AreaLoadStaging()
// Preconditions: Location codes have been written to 801CCB, 801CCD 801CC9
// Expected behavior: Sanitize out bad location codes (e.g., bad
// AreaNumbers) and call a common function AreaLoadHelper().
// AreaLoadHelper() is a common channel used during both password-based
// loading and normal level loading as you move from one place to another
// in the game.
$81/A377 E2 30 SEP #$30
$81/A379 AF 0E 1D 80 LDA $801D0E
$81/A37D CF 72 03 80 CMP $800372
$81/A381 F0 76 BEQ $76
$81/A383 AF 72 03 80 LDA $800372
$81/A387 30 70 BMI $70
$81/A389 C2 20 REP #$20
$81/A38B AF C5 1C 80 LDA $801CC5 ; Load the area number.
$81/A38F C9 54 00 CMP #$0054
$81/A392 B0 52 BCS $52 [$A3E6] ; If area number < 54, fall through to
; InvalidAreaNumber_TooLow.
; Otherwise, goto ValidAreaNumber.
InvalidAreaNumber_TooLow:
$81/A394 E2 20 SEP #$20
$81/A396 AF 0E 1D 80 LDA $801D0E
$81/A39A C9 04 CMP #$04
$81/A39C D0 0E BNE $0E
$81/A3AC E2 20 SEP #$20
$81/A3AE A9 00 LDA #$00
$81/A3B0 48 PHA
$81/A3B1 AF 72 03 80 LDA $800372
$81/A3B5 48 PHA
$81/A3B6 F4 06 00 PEA $0006
$81/A3B9 22 02 80 81 JSL $818002
$81/A3BD 85 34 STA $34 ; Fall through into BadLoop
BadLoop:
$81/A3BF A9 00 LDA #$00
$81/A3C1 48 PHA
$81/A3C2 AF 72 03 80 LDA $800372
$81/A3C6 48 PHA
$81/A3C7 F4 06 00 PEA $0006
$81/A3CA 22 02 80 81 JSL $818002
$81/A3CE C5 34 CMP $34
$81/A3D0 F0 ED BEQ $ED
// This hangs forever :(
ValidAreaIndex:
$81/A3E6 E2 20 SEP #$20
$81/A3E8 A9 00 LDA #$00
//... clipped for brevityThis code snippet makes reference to another function I'm calling AreaLoadHelper. I'm not posting the code to AreaLoadHelper because it's veering a bit off topic. If you want to see the code for that, it's here. Look for 'Function: AreaLoadHelper() - 801D0D'.
Looking through, it's possible they originally intended for bad location codes to do something more elegant than a hang in this function (early out?). Or perhaps not, if they were sure this code wasn't reachable.
Anyway, changing
$81/A38F C9 54 00 CMP #$0054to
$81/A38F C9 0C 00 CMP #$000C fixes it here. The AreaNumbers for the last two levels are 0051 and 000C, so 0C covers it. The fact that it's the same number as patched above is really a coincidence.
If you were to apply this change and run the game, you would still see the same symptom as before where the screen would fade to black yet no level would get loaded. This is because it gets further in the level-loading code before getting stuck again. It was a very loose spin. I had an unpleasant debugging experience. That's because if you break in the debugger while it's hanging, you're too late. The root cause of the hang was here
// Function: CallAreaLoadHelperArg4 ($81:A33A)
// Preconditions: An AreaNumber is passed in through address $80:1CC5.
// Expected result: Validate the AreaNumber.
// If valid, push the argument '4' onto the stack and then call AreaLoadHelper(),
// a common code path shared between password-loading usual traversal
// through the game world.
$81/A33A E2 30 SEP #$30
$81/A33C AF 0E 1D 80 LDA $801D0E
$81/A340 CF 72 03 80 CMP $800372
$81/A344 F0 2E BEQ $2E
$81/A346 AF 72 03 80 LDA $800372
$81/A34A 30 28 BMI $28
$81/A34C C2 20 REP #$20
$81/A34E AF C3 1C 80 LDA $801CC3
$81/A352 C9 EF 00 CMP #$00EF
$81/A355 F0 09 BEQ $09
$81/A357 AF C5 1C 80 LDA $801CC5
$81/A35B C9 54 00 CMP #$0054 ; Load AreaNumber
$81/A35E 90 14 BCC $14 [$A374] ; If too low, goto InvalidLocation.
; If okay, fall through to ValidAreaNumber
ValidAreaNumber:
$81/A360 E2 20 SEP #$20
$81/A362 A9 00 LDA #$00
$81/A364 48 PHA
$81/A365 AF 72 03 80 LDA $800372
$81/A369 48 PHA
$81/A36A F4 00 01 PEA $0100
$81/A36D F4 04 00 PEA $0004 ; Push args
$81/A370 22 02 80 81 JSL $818002[$81:8002] ; Call AreaLoadHelper()
InvalidLocation:
$81/A374 C2 30 REP #$30
$81/A376 6B RTL Another place where the validation is on the wrong bounds.
So, change
$81/A35B C9 54 00 CMP #$0054 to
$81/A35B C9 0C 00 CMP #$000Callowing through both within-Moria area numbers, it works.
It is kind of good password-resuming the last two areas was something superficial like this, and not a deeper problem like a huge swath of level loading being actually not implemented. It turns out, the odds a "not implemented" is low anyway, since that part was written in a reasonable way- i.e., if you can visit an area, you can password-resume to it. They share the same code.
As for the fix since the total amount of changes is small, you could use a ROM patch, but it's even easier as a cheat code like a Pro Action Replay code. Expressing the above changes as SNES Pro Action Replay the codes are
81CBF10C
81A3900C
81A35C0CThese are value changes to ROM code (it is not self modified), so if you're applying cheats in an emulator you don't need to re-start the game to apply them.
Here is a demo of the codes in action
I was gonna post this to GameFaqs but they have this

oh well.
Anyway, you can use the cheat codes in a Pro Action Replay device for Super Nintendo, or any mainstream emulator (tested ZSNES, Snes9x) to unblock the game. Enjoy
Suppose you have a Win32 program with a checkbox. You just added it. No changes to message handler.
You click the box. What happens?
Answer: the box appears checked. Click it again, the box becomes un-checked. Riveting
Now suppose you have a Win32 menu item that is checkable. Again, added with no changes to message handler.
You click the item. What happens?
Answer: Nothing. It stays checked, if it was initialized that way. Unchecked, if it was initialized that way.
In both these cases, the item was added straightforwardly through resource script with no changes to the message handler.
Why are these two things different?
Explanation: apparently it falls out of broader Win32 design. The automatic-ness that the normal checkbox has, requires features to control it. For example, those checkboxes can be grouped into radio button groups with WS_GROUP. To add that same richness to menu items, too? You could, but it'd be an increase in complexity, and the benefit would need to be clearly justified. There'd need to be an "MF_GROUP" and all the API glue that comes cascading with it. Also, automatic checkbox-ness brings with it the chance of encountering errors, and errors tends to mean modal dialogs. It's okay to launch dialogs during normal window interactions, that happens all the time. But from a menu item? It would be really jarring and unexpected. Going more broadly than that it runs the risk of encouraging of bad habits: you might use the hypothetical "MF_GROUP" glue to do something strange and expensive, and that's not what menu items are for. Since it's not clear the benefit is justified, you're on your own for check state.
In case you were wondering, I'm not really trying to "sell" this inconsistency to you. I was just as surprised as you were. I am trying to explain it based on sources though. It's not random.
Something related- this docpage, "Using Menus - Simulating Check Boxes in a Menu". The sample code leaves you asking some broader questions of "why am I doing all this?"
Raymond Chen article fills in blanks: "Why can't you use the space bar to select check box and radio button elements from a menu?"
The design is also conveyed through Petzold's "Programming Windows, 5th edition" page 445 in the code sample "MENUDEMO.C". The message handler goes like
case IDM_BKGND_WHITE: // Note: Logic below
case IDM_BKGND_LTGRAY: // assumes that IDM_WHITE
case IDM_BKGND_GRAY: // through IDM_BLACK are
case IDM_BKGND_DKGRAY: // consecutive numbers in
case IDM_BKGND_BLACK: // the order shown here.
CheckMenuItem (hMenu, iSelection, MF_UNCHECKED) ;
iSelection = LOWORD (wParam) ;
CheckMenuItem (hMenu, iSelection, MF_CHECKED) ;The general trend in this book is to leverage automatic facilities in the Win32 API wherever it makes sense to do. But here, the radio button-ness is all programmatic for checkable menus.
This post describes how to change players' names arbitrarily (longer or shorter) in the game NHL '94 for Super Nintendo by changing the ROM.
Players' names are shown as text in the menus and in-game.
In the team selection menu, it's their first initial and last name. In other places, it's the full first and last name.
Goal is to change how names appear in all these places. Have new names' length be allowed to be different from the old names.
My own intended usage for this is to only change a few names, so optimize for that. And optimize for game stability because I plan to play the game, not just do a quick demo. I don't care if the result is not elegant or wasteful in terms of memory. The result can operate on an expanded ROM.
The Very Easy, Very Limited Way
Easiest way to change names is a pure data hack. Doesn't require any knowledge about SNES at all, only basic computer literacy. Open the ROM in a hex editor such as HxD. Scroll down until you see players' names on the right, and type over them. Hit Ctrl+S to save. Start your game and go.
Why does this work? Because all player names are literally stored as ASCII, no need for character translation tables or whatever. Also, each name is only stored in 1 place for the most part.
But of course, the catch is whatever new name you pick has to be the same length or shorter. Ideally, the same length. Shorter only kind of works because you can pad names with spaces, but no guarantees that'll look right when you see it laid out on the screen. And if the new name is longer it definitely won't work. Since the goal is to let you change names without length restrictions we have to do something more.
The reasons why you can't change the name length as a pure data hack take some context to explain. So they are explained further down. The first thing you need to know is the data you just tried to hack- what is it, really.
Player-data Format
This describes where and how players' names are stored in the ROM, as well as the neighboring data.
There is what I'm calling a "main pointer table". The table has 28 values. This table is stored at ROM address 0x9CA5E7.
If you dump the raw data for the table it's
4F EB 9C 00 AC AB 9C 00 32 AE 9C 00 C1 B0 9C 00
40 B3 9C 00 4F C0 9C 00 D7 B5 9C 00 9D B8 9C 00
4D E9 9C 00 1D BB 9C 00 B2 BD 9C 00 DB C2 9C 00
7E C5 9C 00 2B C8 9C 00 9C CA 9C 00 06 CD 9C 00
AC CF 9C 00 37 D2 9C 00 D2 D4 9C 00 60 D7 9C 00
D4 D9 9C 00 4A DC 9C 00 DC DE 9C 00 7E E1 9C 00
AD E6 9C 00 05 E4 9C 00 57 A6 9C 00 04 A9 9C 00Formatted nicely, the table is
int mainTable[] = {
9CEB4F, // Anaheim
9CABAC, // Boston
9CAE32, // Buffalo
9CB0C1, // Calgary
9CB340, // Chicago
9CC04F, // Dallas
9CB5D7, // Detroit
9CB89D, // Edmonton
9CE94D, // Florida
9CBB1D, // Hartford
9CBDB2, // LA Kings
9CC2DB, // Montreal
9CC57E, // New Jersey
9CC82B, // NY Islanders
9CCA9C, // NY Rangers
9CCD06, // Ottawa
9CCFAC, // Philly
9CD237, // Pittsburgh
9CD4D2, // Quebec
9CD760, // San Jose
9CD9D4, // St Louis
9CDC4A, // Tampa Bay
9CDEDC, // Toronto
9CE17E, // Vancouver
9CE6AD, // Washington
9CE405, // Winnepeg
9CA657, // All Stars East
9CA904 // All Stars West
};There is 1 value per hockey team.
The first element in the array belongs to Anaheim, and the value is 0x9CEB4F.
The second element in the array belongs to Boston, and the value is 0x9CABAC, and so on.
The teams are ordered alphabetically, except for the all-stars teams at the end. The values themselves aren't in any particular order.
Although the all-stars teams are comprised of players which exist on other teams, they have their own entries in the table. That's the game opting for perf and simplicity of code in the perf-memory tradeoff.
Looking at the values of elements in this array, you might think they also look like ROM addresses and you would be right.
As for what's stored at each address- here's a description
[H0] [H1] [some number of header bytes] // A two-byte low-endian length H, and a variable-length
// header stream of length H-2
For each player:
[L0] [L1] [player's name] // A two-byte low-endian length L, and then a variable-length string
// of length L-2
[PlayerNumber] // A byte for the player number. It's in a decimal format.
// Leftmost half-byte is the tens place value. Rightmost half-byte is
// the ones place value.
[WeightClass, Agility] // A byte. Leftmost half-byte is the player's weight class.
// Rightmost half-byte is their agility rating.
// Weight class is displayed as a measurement in pounds when
// displayed on the team roster page.
// To convert from weight class to pounds, it's
// pounds = 140 + (weightClass * 8)
// Weight classes range from 0 to 14 in practice. Higher numbers may
// be hacked.
// Agility rating is from 0 to 6.
[Speed, OffenseAware] // A byte. Leftmost half-byte is player's speed. Rightmost half-byte
// is their offense awareness rating.
// Ratings are from 0 to 6.
[DefenseAware, ShotPower] // A byte. Leftmost half-byte is player's defense awareness rating.
// Rightmost half-byte is their shot power.
// Ratings are from 0 to 6.
[Checking, Handedness] // A byte. Leftmost half-byte is player's checking rating. Rightmost
// half-byte is their handedness.
// Checking rating is from 0 to 6.
// For handedness, if the value is even (divisible by 2) they shoot
// left. If it's odd they shoot right.
[StickHandling, ShotAccuracy] // A byte. Leftmost half-byte is player's stick handling rating.
// Rightmost half-byte is their shot accuracy.
// Ratings are from 0 to 6.
[Endurance, Roughness] // A byte. Leftmost half-byte is player's endurance rating. Rightmost
// half-byte is their 'roughness' rating.
// Ratings are from 0 to 6.
// The 'roughnesss' stat is a hidden stat. It exists but is not
// displayed in the game or the manual.
[PassAccuracy, Aggression] // A byte. Leftmost half-byte is player's pass accuracy rating.
// Rightmost half-byte is their aggression rating.
// Ratings are from 0 to 6.
Then, at the end:
[00] [00] // Two zero bytes mean that's the end of the player data for this
// team.For example, if we dereference and dump what's stored at 9CC2DB (Montreal), we get
55 00 0E 00 79 02 1D 00 0E 00 13 00 15 00 52 11
21 E8 49 C5 00 01 12 11 07 03 0C 04 00 01 17 12
07 03 0C 04 00 01 16 11 08 04 0E 03 00 01 13 14
09 05 0D 03 00 01 12 11 07 03 0C 05 00 01 13 14
08 04 05 03 00 01 11 17 07 06 03 0D 00 01 16 13
03 0D 07 06 00 0D 00 50 61 74 72 69 63 6B 20 52
6F 79 33 66 44 46 00 00 55 66 ...Cleaned up, this is
Cleaned up, this is
headerSize = 0x0055;
byte header[] = {0E 00 79 02 1D 00 0E 00 13 00 15 00 52 11
21 E8 49 C5 00 01 12 11 07 03 0C 04 00 01 17 12
07 03 0C 04 00 01 16 11 08 04 0E 03 00 01 13 14
09 05 0D 03 00 01 12 11 07 03 0C 05 00 01 13 14
08 04 05 03 00 01 11 17 07 06 03 0D 00 01 16 13
03 0D 07 06 00 };
player0 = {
// L0 L1 P a t r i c k __ R o y
0D 00 50 61 74 72 69 63 6B 20 52 6F 79 // "Patrick Roy"
// 11 character length +
// 2 byte string size = 13 = 0xD, converted to
// two-byte low endian that's 0D 00
33 // Number 33
66 // Weight class 6, agility 6
44 // speed 4, OffAware 4
46 // DefAware 4, shot power 6
00 // checking 0, handedness L
00 // stick handling 0, shot accuracy 0
55 // endurance 5, roughness 5
66 // pass accuracy 6, aggression 6
}
Etc, for the rest of the players. Then there are some team-related strings at the end.
Heads up that viable (e.g., a subsequent team's) game data can follow immediately after the data for each team. So no, you're not free to grow things off the end.
Side thing: stats stored affect the stats in-game although you'll notice they don't correlate to those stats exactly. That's because each game applies RNG. Try it yourself if you want. Boot the game, pick two teams and look at a player's stats. Reset the game, pick the exact same matchup and player to look at. The stats will be slightly different. If you play a lot of sports games maybe this is not surprising. There is this real-world idea that any team could potentially beat any other team.
Strings are stored with a length rather than being delimited, so that's nice. However, there's a bunch of player data parsing code that needs to skip over player's names to get to their stats. So if you make a player's name shorter, you'd need to either pad with spaces (could cause things to display weirdly) or update the length value and move that person's stats plus everyone else on the team's data backwards. I've listed all the stats out because you need to know how much to move if you do it that way, and it's also helpful to know what it is you're moving.
And of course for making player's names longer, there isn't any extra space off the end, so you need something else entirely. This was the case I was more interested in.
Why not move the whole team data, and update the "main pointer table" entry?
This seemed like a swell idea at first. To get names as long as you want, just make a totally new copy of the player data someplace else with your new names, then adjust the "main pointer table" value to point to it.
Unfortunately that won't work. It is true the "main table" above is a table of long (four-byte) pointers. But, the upper two bytes of each entry are either
- dead data, sometimes
- dead data, always
By "dead data" I mean the data isn't read and doesn't do anything.
Instead of reading data from the upper two bytes, the game will use a hardcoded number which is $9C.
Here's an example of what I mean. This is from the code to figure out a player's first initial and last name for the team selection screen.
; Precondition: 9F1CDC and $9f1CDE have been
; initialized with
; main table elements for home and away teams
; respectively.
; We're in 16-bit mode.
;
$9F/C732 A9 9C 00 LDA #$009C ; Hardcode $9C in the upper part
$9F/C735 85 8B STA $8B
$9F/C737 A4 91 LDY $91
$9F/C739 B9 DC 1C LDA $1CDC,y[$9F:1CDC] ; Load the short pointer from the main table
$9F/C73C 85 89 STA $89 ; Store the short pointer in the lower part
;
; ... do stuff that uses direct addressing on
; 24-bit pointer. For example, ADC [$89].
There are multiple instances of this pattern. I found several without trying super hard and I believe there are more. If you want to change a "main pointer table" entry, you don't just change the entry- you need to change some undetermined number of places in game code.
Why store long pointers in the table if they were gonna do it this way? They could have just stored short pointers. Seems like a waste of space. It might have been, they started out planning for long pointers but wanted to optimize reading/dereferencing of the table values, then they never tried to go back and shrink the table.
Anyway, it's hard to safely detect all the places that pull values out of this table so it's difficult to "fix" the table and reclaim the space. I didn't try. If you want to try it to be absolutely safe you might want to set a breakpoint in the debugger and play the game extensively. We don't have source code and you can't statically disassemble this platform.
So suppose you begrugingly accept the fact that all table entries need to live in bank $9C. Can you change lower bytes only and make that work? Unfortunately that's not such a good idea either. You can adjust these table values to point someplace else in bank $9C, but there isn't all kinds of free space in that bank to put anything.
If we want to move player data (including player names' string data) to a different location in memory, a different bank- I prefer a safer option that is more targeted. Completely bypass the use of the "main pointer table" entry JUST when we are loading player names. This lets us be really confident in things working. We make a code change in a specific, testable place that we understand really well.
Detouring the loading of player names
NHL '94 has a function I'm calling LookupPlayerName().
The code for LookupPlayerName() is
; Function: LookupPlayerName()
; Gets the address of a player's name string,
; based on the player's index on the team and some
; previously-set table data.
;
; Preconditions:
; $91 contains HomeOrAway. 0 == home, 2 == away
; $9F1CDC and $9F1CDE have been initialized with
; main table elements for home and away teams
; respectively.
; $A5 contains PlayerIndexOnTeam
;
; Postconditions:
; $89-$8B = Address of the player's name string
; data. (Includes the length field that comes first)
;
; $A5 gets scrambled.
$9F/C732 A9 9C 00 LDA #$009C ; Hardcode 9C in the upper bytes. Easy enough.
$9F/C735 85 8B STA $8B [$00:008B] ;
;
$9F/C737 A4 91 LDY $91 [$00:0091] ; Load the choice of HomeOrAway. 0 == home, 2 == away
$9F/C739 B9 DC 1C LDA $1CDC,y[$9F:1CDC] ; Load PlayerNamesStartAddress for the corresponding
; team.
; As mentioned in the preconditions this has been set
; up for us. As it happens, it's somewhere far away in
; the chain of function calls.
$9F/C73C 85 89 STA $89 [$00:0089] ; And then store the lower bytes.
LookupPlayerName_GetOffsetOfPerPlayerData:
$9F/C73E A0 00 00 LDY #$0000
$9F/C741 18 CLC
$9F/C742 67 89 ADC [$89] [$9C:C2DB] ; Use the fact that the first two bytes of the
; PlayerNamesStartAddress
; data will give us the offset to the per-player data.
$9F/C744 85 89 STA $89 [$00:0089] ; For example, for Montreal we add 0x55 to get to the
; start of the per-player data.
$9F/C746 80 0A BRA $0A [$C752] ; Goto LookupPlayerName_CheckDone
LookupPlayerName_ForEachPlayerIndexOnTeam:
$9F/C748 A5 89 LDA $89 [$00:0089] ; Load the length of the player's name.
$9F/C74A 18 CLC
$9F/C74B 67 89 ADC [$89] [$9C:C330] ; Increment the current $89-$8B pointer by the length
$9F/C74D 69 08 00 ADC #$0008 ; Plus 8, it's padding (Not really but let's pretend
; it is)
$9F/C750 85 89 STA $89 [$00:0089] ; Update the current $89-$8B pointer
LookupPlayerName_CheckDone:
$9F/C752 C6 A5 DEC $A5 [$00:00A5]
$9F/C754 10 F2 BPL $F2 [$C748] ; branch-if-positive
; LookupPlayerName_ForEachPlayerIndexOnTeam
$9F/C756 6B RTLThe idea is to detour this function. Use an "alternate main table" which actually does honor the long pointer, and shim LookupPlayerName() to use the "alternate main table" instead. From testing I found that LookupPlayerName() is a centralized place and changing it is sufficient.
How the detouring goes is we chuck a payload someplace there's space (say, $A08100, in expanded ROM space). Then replace the code for LookupPlayerName() with
$9F/C732 5C 00 81 A0 JMP $A08100 ; Jump into expanded ROM space where we put the
; detour payload
NOP
NOP
...NOPs are not strictly needed but added for hygiene. (Could use a BRK instead when you are getting things running)
As for the payload itself, it's
$A0/8100 DA PHX ; Caller doesn't like it if X is scrambled
A4 91 LDY $91 ; Load the team index, which has been stored at
; 9F1C98/9F1C9A for home/away.
B9 98 1C LDA $1C98, y[$9F:1C98]
0A ASL ; Multiply by 4 to turn index into an offset
0A ASL
AA TAX ; Use the team index to look up into the
; "alternate main table".
BF 00 D0 A8 LDA 0xA8D000,x ; Load the array element from 0xA8D000, store it in
; $89-$8C
85 89 STA $89
E8 INX
E8 INX
BF 00 D0 A8 LDA 0xA8D000,x
85 8B STA $8B
; The "alternate main table" is formatted a bit
; differently from the "main table".
; Each element is itself an array, one four-byte
; element per player.
; Use $A5 as a counter to get to the right player.
PlayerIndexIncrement:
A5 A5 LDA $A5 ; Sets Z
F0 0C BEQ $0C ; goto DonePlayerIndex
E6 89 INC $89
E6 89 INC $89
E6 89 INC $89
E6 89 INC $89
C6 A5 DEC A5
80 F0 BRA $F0 ; goto PlayerIndexIncrement
DonePlayerIndex:
; We have the element for the right player stored
; at $89-$8C.
; The element is a pointer.
; It'll be either $9Cxxxx if we're keeping the
; original names, or $A8xxxx/whatever if
; we're using new names.
; Dereference it, and store the dereferenced result
; at $89-$8C.
A7 89 LDA [$89]
48 PHA
E6 89 INC $89
E6 89 INC $89
A7 89 LDA [$89]
85 8B STA $8B
68 PLA
85 89 STA $89
FA PLX ; Restore X and return.
6B RTLOne thing that allows the detour to work is there's nothing in the detour that requires execution out of bank $9F (bank $9F is where the original function is). It's okay if the code executes in bank $A8. And by a stroke of good fortune, it happens that the original code is also okay running from other banks. No absolute short addressing (local bank). This is hugely helpful when getting things up and running.
The "alternate main table" lives at 0xA8D000, chosen arbitrarily.
If this code were a bit smaller it could actually be copied overtop the implementation of LookupPlayerName() with no jumping out. Original LookupPlayerName is 37 bytes, this routine is 55 bytes. Alas, it won't fit, so I put it at $A08100. Not a big deal since we are putting stuff in expanded ROM space anyway.
Putting it all together, the full list of things to patch are
- the JMP at the beginning of LookupPlayerName
- code snippet above it's supposed to JMP to
- the "alternate main table" at 0xA8D000 and set of tables each of its entries points to
- the strings that the "alternate main table" points to
Not too bad.
Could do all this manually. I suggest making a program to do it so that you don't make mistakes. And plus you can easily configure whatever new player names you want. I made an editor that does the above.
Example in the editor:
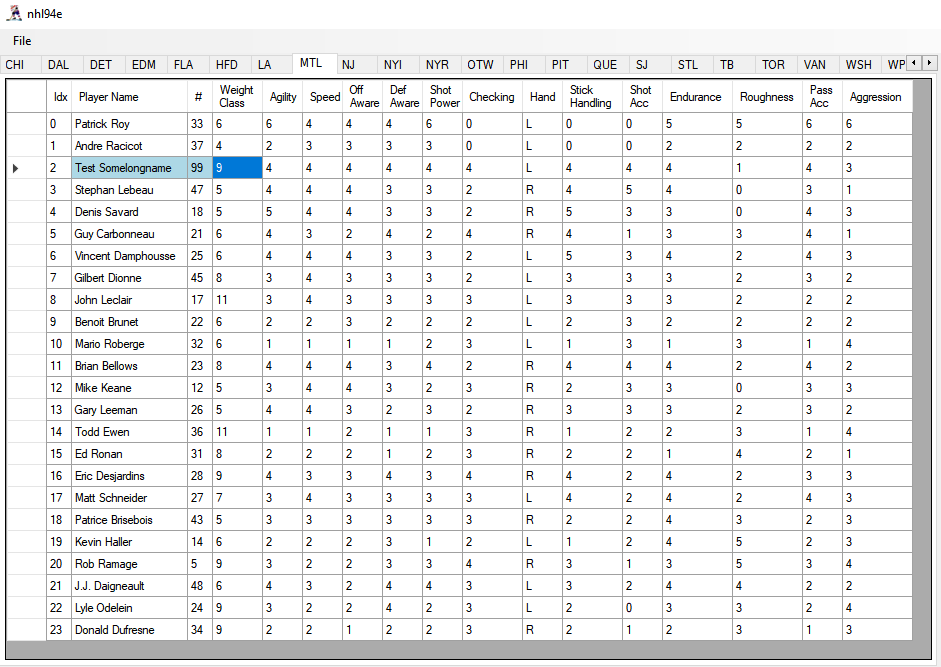
Patched game result
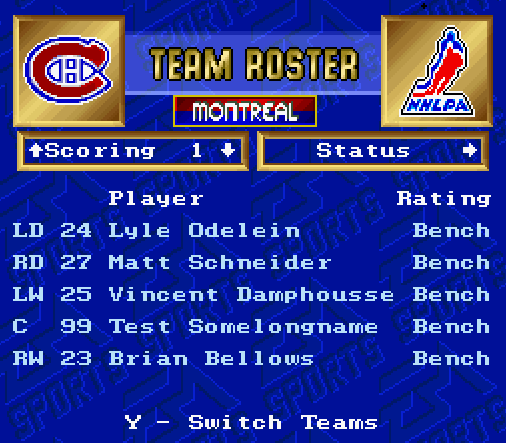
Enjoy
Download the editor here:
https://github.com/clandrew/nhl94e/releases/tag/v1.0
Or, find the editor source code here
https://github.com/clandrew/nhl94e
Find this post, in text form here:
https://raw.githubusercontent.com/clandrew/nhl94e/main/docs/PlayerNames.txt